Markdown is not agent memory
Some of the most capable agents in production keep their memory in plain markdown files, and for a single agent and a single user it is hard to beat. The pattern breaks in predictable places: at scale, as facts change and errors compound, and under concurrent agents.


Key takeaways
- Markdown memory is a legitimate pattern. Manus runs "filesystem as context" at millions of users; Claude Code and Letta's MemFS keep agent memory in markdown files. For a single agent and a single user it is simple and runs with no infrastructure.
- The markdown benefit that "a human can review it" is mostly theoretical. The agent writes its own memory and the files are seldom read, so the store has to stay correct without a curator.
- Errors compound. A file records what was written, not what it replaced or why, so later turns build on bad facts. Git tracks line edits, not a fact's validity or source, and doesn't reconcile contradictions.
- Concurrent agents diverge. Without git, writes to one file race; with git, related files diverge logically with nothing to reconcile them against the source.
- The fixes turn memory into a system. Recording when a fact was true and where it came from is more than a file holds, and it is the point where a database or a temporal graph earns its place.
What markdown memory does well
A directory of markdown files is the right tool when the scope is narrow. Coding assistants are the clearest case. Files such as CLAUDE.md or the cross-tool AGENTS.md standard record project conventions and instructions an agent loads each session, and auto-memory lets the agent keep its own notes between runs. The store is free and runs with no service to operate.
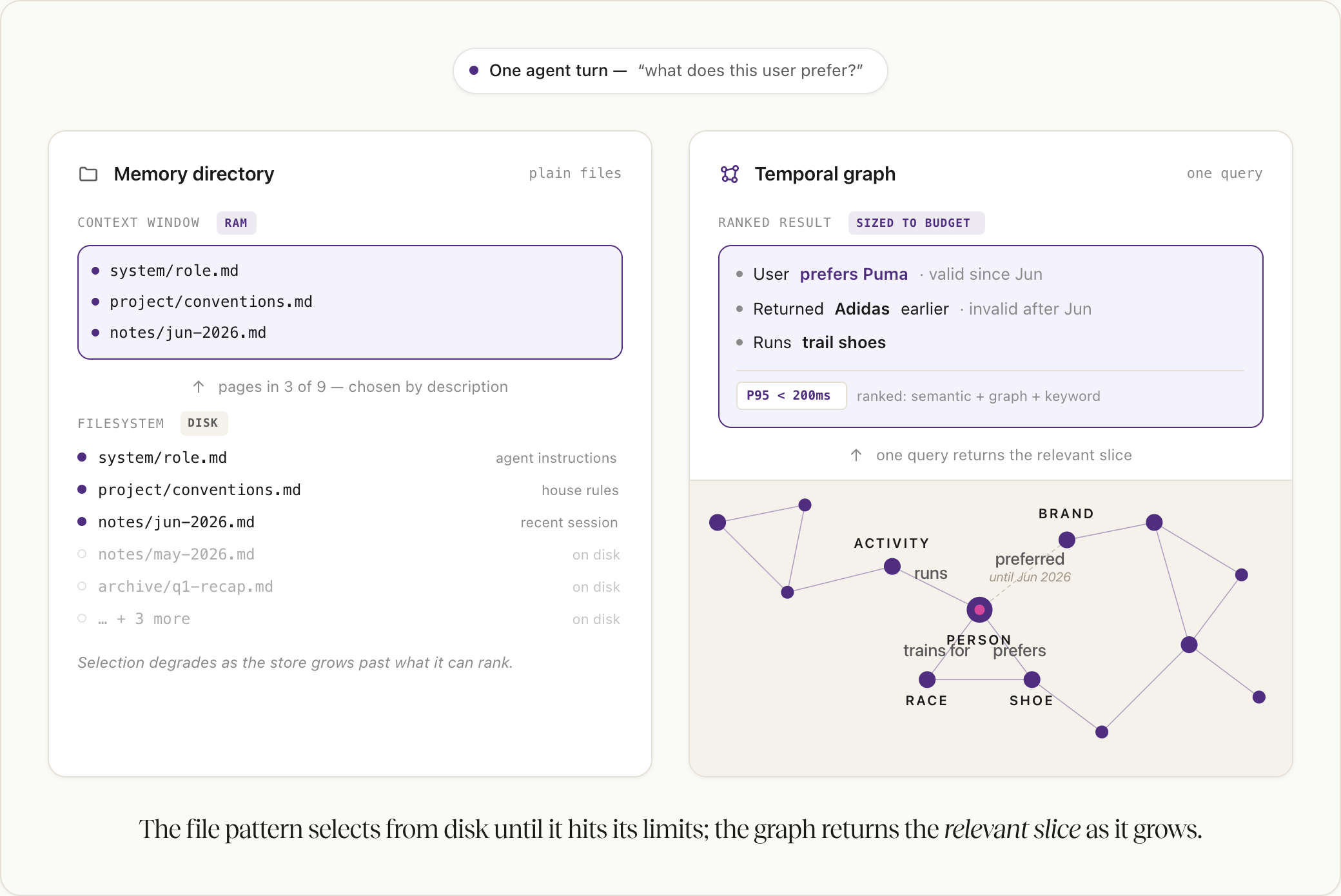
The best implementations are more disciplined than a single growing file. Anthropic calls the principle progressive disclosure: the context window is finite, so the agent pulls in only the context a step needs. Letta's MemFS keeps a system/ directory always in context and exposes the rest as filenames and descriptions, and loads contents only when needed. Manus keeps state restorable rather than resident: it drops a web page's content from context as long as it keeps the URL. The filesystem is disk to the context window's RAM, and the agent pages in what it needs.
One advantage gets oversold. The store is plain text, so the pitch is that a human reviews and curates it, and Letta backs its files with git so there is a history to read. In practice the agent does the writing and a person rarely audits the result, so markdown memory has to stay correct without a curator. For a single-subject assistant on one machine, reaching for a database or a graph would be cost without benefit. The rest of this post is about what happens when the workload widens.
Retrieval and scale
Choosing which files to load is itself a form of retrieval, and that approach works until there are more files than the agent can reliably choose between. A model choosing from a list of file descriptions has less to go on as the list lengthens, which is why the documented designs push toward consolidating memory rather than letting it accumulate.
When the number of files grows past what the agent can reliably pick from, the obvious next step is a vector store. For memory, though, it solves the wrong problem. A vector store is a similarity index, and similarity is not relevance. It ranks by embedding distance, so a fact from six months ago scores the same as yesterday's when the text matches, and it has no mechanism to supersede a fact when it changes: a user who moves from Python to Rust leaves both statements in the store as independent vectors. It cannot traverse the relationship between two facts, and it treats an unverified aside as equal to a verified record. A vector index makes the store bigger without making it memory.
What scaling memory actually needs is ranked retrieval that stays fast as the data grows and still weights how recent and how true each fact is. A flat file and a vector index lack both.
History and provenance
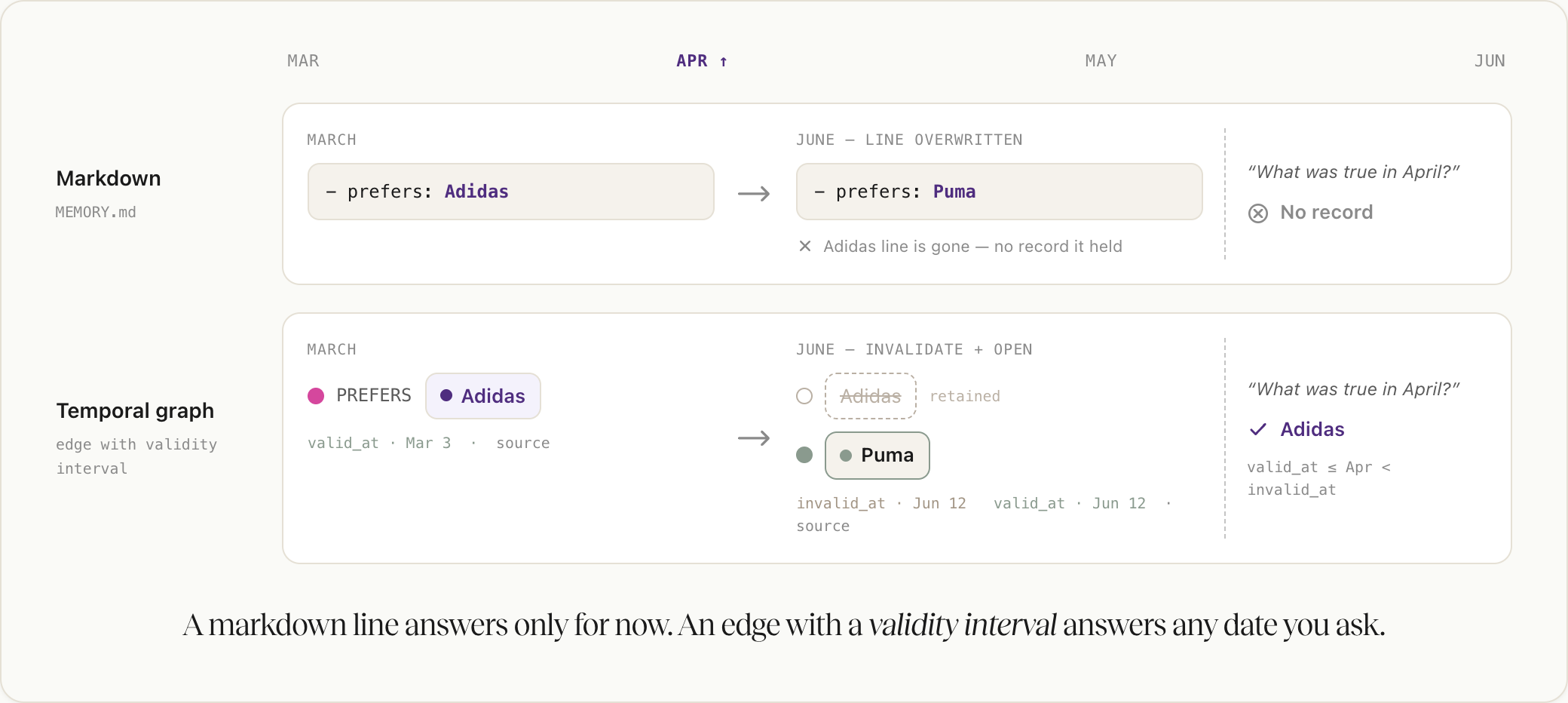
A markdown file records what is written, not what it replaced or why. When a fact changes, the agent either overwrites the old line, which destroys the history, or appends the new one, which leaves the file holding both. Neither path records that one fact superseded another, or where either came from. A later agent treats the surviving line or the contradiction as settled and acts on it. The error compounds as each turn builds on the last.
Git does not close this gap, even though it looks like version history. It tracks who changed which line and when, not what a fact was derived from or when it was true. It reconciles text, not meaning, so two commits that each merge cleanly can still leave the memory logically inconsistent.
Re-deriving from a source of truth is the practice that keeps file memory honest, and it has a precondition. Anthropic's progressive-disclosure guidance is to retrieve current state at runtime rather than cache it, so an agent can grep the repository to confirm a function still exists before relying on a line that names it. That works because the source is local and cheap to re-check. Business facts have no such backstop. Why an account was flagged, or what a user preferred last quarter, sits in no local file to re-derive, so a wrong line stays wrong.
Catching this needs two things a file does not record: when each fact was true, and where it came from. With validity intervals, an agent can ask what held on a given date; with a link from each fact to its source, it can check why it believes a thing. A line of prose carries neither.
Concurrent agents
Multiple agents sharing one memory hit two problems. Without git, two agents writing the same file at once have no reliable lock. File locking is inconsistent across platforms and breaks on network filesystems, so the writes race and clobber each other.
Git serializes commits and merges text, which removes the race for a single file but not the harder problem. When agents write to different but related files at the same time, each commit can be clean while the facts across them diverge: one file now says a project shipped, another still says it is in review, and nothing reconciles the two against the data they came from. Building that reconciliation step means going back to the source to decide which version holds, and teams rarely build it, so the divergence persists until someone notices.
Reconciling concurrent writes means resolving them against the source and the timeline, not merging text. That is a property of the data model, and a directory of files does not have it.

Access control and retention
A second user changes the problem. File permissions decide who can open the file, but they cannot express that an agent acting for one user may see that user's facts and no one else's when all the facts share a directory. Once teams or compliance boundaries enter, memory becomes a governance problem. Deletion in a file is a manual edit with no record that it happened: no retention policy and no audit of what was removed or when.
These controls have to sit below the memory layer and apply on every read and write, with an audit trail the file format cannot keep. Once more than one person's data is in scope, that is not optional.
Where markdown memory falls short
| Concern | Markdown memory | What a fix requires |
|---|---|---|
| Retrieval at scale | Whole-file selection; degrades as it grows | Ranked retrieval that stays fast |
| Changing facts | Overwrites or piles up; no history | Validity intervals; point-in-time queries |
| Provenance | None; git logs commits, not facts | Each fact linked to its source |
| Concurrent agents | Races without git; diverges with it | Reconciliation against source and timeline |
| Governance | File permissions; manual deletes | Isolation, retention, and audit below the layer |
Where the file pattern breaks, and the capability each gap requires.
What a temporal graph changes
These problems share a root: a file stores text, and memory needs structure. A temporal knowledge graph supplies it. Facts become edges with validity intervals, so a change extends the history instead of overwriting it, and each fact links to the source it was extracted from. New writes are reconciled against the graph and the timeline rather than merged as text. Zep builds this on the open-source Graphiti framework and reports sub-200ms retrieval as the graph grows (arXiv:2501.13956). If you would rather run it yourself, Graphiti is the same engine.
How to choose
The decision turns on four questions. How many agents and users share the memory? Do facts change, so the memory has to keep them reconciled? Do facts come from sources the agent cannot re-derive locally? Does the data fall under a retention or compliance regime?
For one agent, one user, a local source of truth, and no compliance surface, markdown memory is the proportionate choice, and the best implementations stretch it further with discipline: they select rather than dump, and keep only what cannot be re-derived. When several of those answers change, the file pattern stops being cheap. Errors compound with no history or provenance to catch them, and concurrent agents diverge. A second user adds isolation and audit requirements. At that point memory is a system to build, adopt, or buy.
Frequently asked questions
Is markdown memory good enough for an AI agent? For one agent serving one user, with a local source of truth to re-derive from, markdown memory is often the right choice. It is free and transparent, which is why coding assistants like Claude Code and frameworks like Letta use it. It stops being enough when a second agent or user, changing facts, or a retention requirement enters the picture.
Does markdown memory scale? It scales further than a single file suggests, because good implementations load file descriptions and select a few files rather than injecting everything, the progressive-disclosure approach Anthropic recommends. That selection still degrades as the number of files grows past what a model can reliably choose from. A vector store is the usual next step, but it ranks by similarity rather than recency or truth and cannot update a fact when it changes. Scaling memory needs ranked retrieval that respects how recent and how true a fact is.
What actually goes wrong as a markdown memory grows? Errors compound. A file records what was written, not what it replaced or why, so a wrong or superseded fact sits there and later turns build on it. Git records who edited which line, not a fact's validity or where it came from, and it does not reconcile logical contradictions. The result is memory that drifts from the truth with nothing in the format to catch it.
Can multiple agents share a markdown memory file? Not safely. Without git, concurrent writes to one file have no reliable lock and race. With git, textual merges resolve a single file, but facts written across related files diverge logically and nothing reconciles them against the source. Reconciling concurrent writes safely needs a data model that resolves them against the source and the timeline, not a shared file.
Can a markdown file track when facts change over time? Not on its own. A file records what is written, not when a fact became true or false, so the working practice is to avoid volatile facts and re-derive them from a local source. That works for code, where the repository is the source of truth, and breaks for business facts with no local source. Tracking change needs validity intervals and point-in-time queries, which a flat file has no way to express.
How do you trace where a fact in agent memory came from? A markdown line has no origin, and git tells you who committed it and when, not what it was derived from. Tracing it needs every fact linked to the source it was extracted from, so an agent can quote the original and you can audit why the system holds a belief.