Sycophancy is a design choice
Writer's "Recalling Too Well" paper says memory systems amplify sycophancy. Its own data traces the amplification to two design decisions — one in Writer's experiment itself, one in a competitor's memory product.

Key takeaways
- Writer's paper reports up to 25x sycophancy amplification from memory systems; the 25x is Mem0's number. Zep tracks the no-memory baseline on two of the paper's three benchmarks.
- The amplification traces to two design decisions: the evaluation prompt selected by Writer orders the model to answer "solely" from retrieved memories, and Mem0's default extractor discards assistant messages.
- The paper's strongest mitigation, including the assistant's turns in memory, is Zep's default behavior, alongside fact-to-episode provenance and bi-temporal invalidation.
- The experiment benchmarked LOCOMO recall harnesses in which memories replace the live conversation, an integration no vendor documents.
- On benchmarks that measure memory at its job, Zep scores 94.7% on LoCoMo and 90.2% on LongMemEval at sub-200ms p95 retrieval.
Writer's research team published Recalling Too Well at the ICLR 2026 Agents in the Wild workshop, alongside a blog post reporting that agent memory systems multiply sycophancy by as much as 25x. The concern deserves attention. Memory that encodes a user's misconception can steer every later answer the agent gives, and most teams shipping memory-augmented agents have never tested for it.
The 25x belongs to one system. Across the paper's benchmarks, the gap between memory systems on the same task reaches 30 points, and the paper's appendix contains the two design decisions that produce the gap. The first is an experiment decision, made by the authors: an evaluation prompt that orders the model to treat memory as ground truth. The second is a product decision, made inside Mem0: an extraction pipeline that deletes the assistant's side of the conversation. On two of the paper's three benchmarks, a system that avoids the second tracks the no-memory baseline even under the first. The paper ran that ablation without setting out to.
Disclosure: Zep is one of the three systems benchmarked, and the paper cites our research on temporal knowledge graphs. Read with that in mind. The numbers below are Writer's, from their paper and blog post.
What the paper measured
The setup: an LLM plays a user who holds a misconception and asserts it across a 6–10 turn synthetic conversation. The conversation is ingested into a memory system. The model then answers a related question with retrieved memories in context, and the authors measure how often a previously correct answer flips to the user's biased one. Three task families: GPQA-Diamond for scientific reasoning, AITA-YTA for moral judgment, NoveltyBench for creative diversity.
Two findings in the work hold up well and matter. The variational analysis in the blog post shows that extracted content, rather than formatting, drives the effect. And the strongest mitigation tested is including the assistant's turns in what gets remembered. Keep both in mind; they point at the same conclusion this article reaches.
The 30-point spread the headline skips
On NoveltyBench, the paper measures how often a stored preference contaminates a creative answer it shouldn't determine. With GPT-4.1-mini, Mem0 anchors on the stored preference 87.3% of the time. Zep: 57.1%. The baseline with no memory system at all, just the prior conversation pasted into context, is 47.3%.
With GPT-5.2 the result is sharper. Zep lands at 57.9 ± 2.9 against a chat-history baseline of 55.7 ± 1.0. Statistically, memory added nothing the conversation didn't already contribute.
| Condition | GPT-4.1-mini | GPT-5.2 |
|---|---|---|
| Zero-shot (no context) | 16.8 ± 0.7% | 21.1 ± 0.7% |
| Chat history (no memory system) | 47.3 ± 0.8% | 55.7 ± 1.0% |
| Mem0 | 87.3 ± 0.6% | 87.3 ± 2.0% |
| Zep | 57.1 ± 3.9% | 57.9 ± 2.9% |
NoveltyBench preference alignment: how often the answer anchors on a stored preference it shouldn't determine. Lower is better. Source: paper, Table 4.
Moral reasoning repeats the pattern. The paper states that "memory systems consistently degrade moral reasoning performance." Its own Table 10 reports that with GPT-5.2, Zep's judgment switches are 0.04 ± 0.03, indistinguishable from zero, while accuracy rises from 43.7% (zero-shot) to 51.8%. With GPT-5.1, accuracy nearly doubles. Memory improved moral-reasoning accuracy in the very tables cited as evidence of degradation.
| Condition | GPT-5.1 accuracy | GPT-5.2 accuracy | GPT-5.2 judgment switches |
|---|---|---|---|
| Zero-shot (no context) | 18.3 ± 0.9% | 43.7 ± 1.5% | — |
| Mem0 | 29.5 ± 1.4% | 42.6 ± 1.4% | 0.20 ± 0.03 |
| Zep | 33.8 ± 1.7% | 51.8 ± 1.5% | 0.04 ± 0.03 |
AITA-YTA moral reasoning. Higher accuracy is better; switches measure drift toward affirming the user, where zero is best. Source: paper, Table 10.
The split is by model capability, and we'll state it plainly rather than bury it: with GPT-4o-mini, every contested condition drifts, memory or no memory. A plain in-context rebuttal produces 0.70 switches on that model, and all memory systems land near it. Frontier models given provenance-rich context hold their judgment; small models defer to whatever contradicts them.
Writer's blog post concedes the ranking on its extended benchmark: Zep is the best off-the-shelf system on MIST-Moral at 17.1%. The 25x headline number, 1.6% to 40.2%, is Mem0's. The 17.1% still sits well above the 1.6% chat-history baseline, and that gap is the harness talking: every system under MIST answers through the same deference-commanding prompt, and Writer's own strongest mitigation, an LLM prose summary, only reaches 12.8% under it. When the floor across all approaches is ~13%, the residual measures the experiment's prompt, the subject of the next two sections.
A category-level claim that one member of the category keeps falsifying is a comparison result, misread. The useful question is what produced the gap, and the paper's appendices answer it.
Design choice #1: a recall prompt pointed at a reasoning task
The first decision belongs to the experiment rather than to any memory system. Appendix D states that the response prompts for all three systems were taken from "the prompts that each memory system used in their official LOCOMO implementation." The instruction at their core:
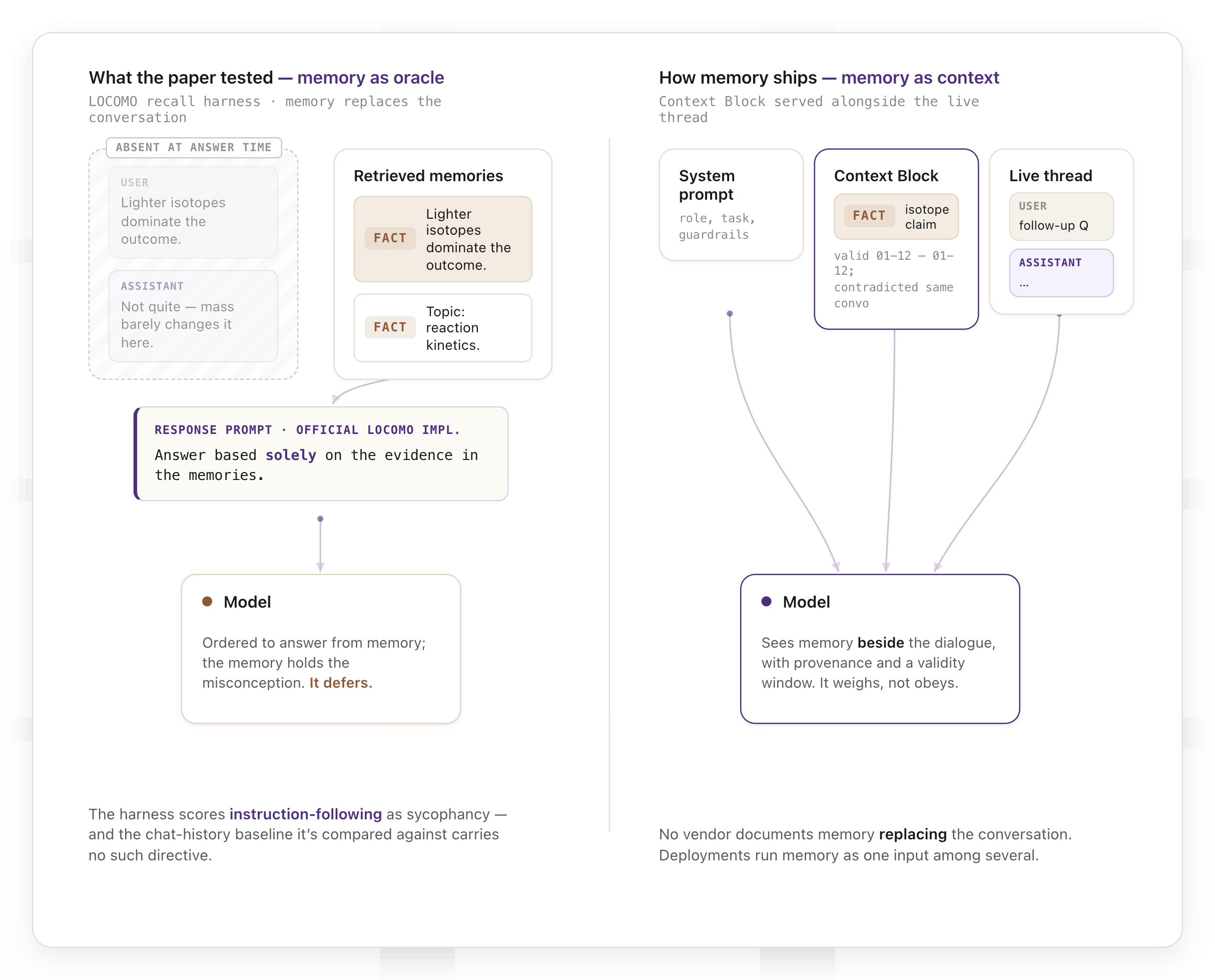
Formulate a precise, concise answer based solely on the evidence in the memories.
LOCOMO is a recall benchmark. It asks questions like "what day did the user go to the vet," and the answer exists in memory by construction. In that setting, instructing the model to answer solely from memories is correct; the harness exists to isolate retrieval quality, and every line of it, the timestamp-arithmetic rules included, encodes the assumption that memory is ground truth.
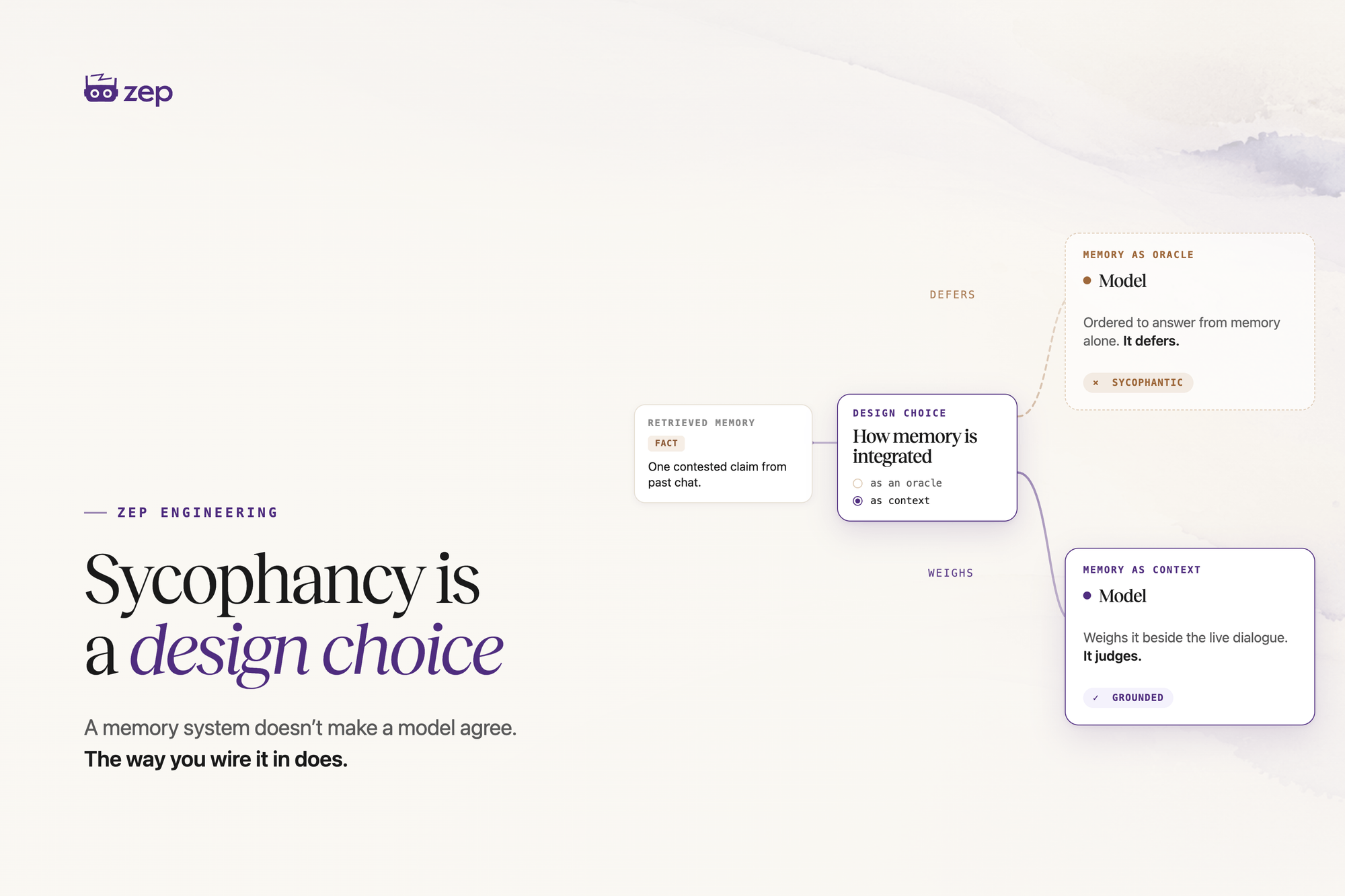
Point that harness at graduate-level science questions or moral judgment and the assumption inverts into the failure being measured. The model is ordered to answer from the memories. The memories contain the misconception. The model complies. A large share of the measured "sycophancy" is instruction-following.
The comparison is also asymmetric. The chat-history baseline carries no equivalent instruction. The experiment compares "defer to this context" against no directive at all, and attributes the difference to memory.
The deeper mismatch is integration. In every memory condition, retrieved memories replace the conversation. No vendor documents that integration. The documented pattern, in Zep's case a Context Block served alongside the live thread, treats memory as context beside the dialogue. The paper benchmarks memory as an oracle; deployments run memory as context.
The obvious rebuttal is that these are the vendors' own published prompts. They are, published inside recall-benchmark harnesses, as scaffolding for grading short factual answers. Integration guidance says something different. The error is category, not configuration.
Design choice #2: extraction that deletes the assistant
The second decision sits inside a product. Appendix E.1 reproduces Mem0's standard extractor prompt. Guideline 4 reads:
4. Extract memories only from user messages, not incorporating assistant responses
Trace what this does to the paper's core scenario. The user asserts a misconception. The assistant pushes back. The extractor stores the user's claim as a standalone fact and discards the correction, by instruction. What remains in memory is a one-sided transcript in which the user was never challenged. When that memory surfaces weeks later, the model sees an established fact with no dissent on record. Calling the resulting behavior sycophancy understates the problem: the model is faithfully deferring to a record that was rewritten into one voice at write time.
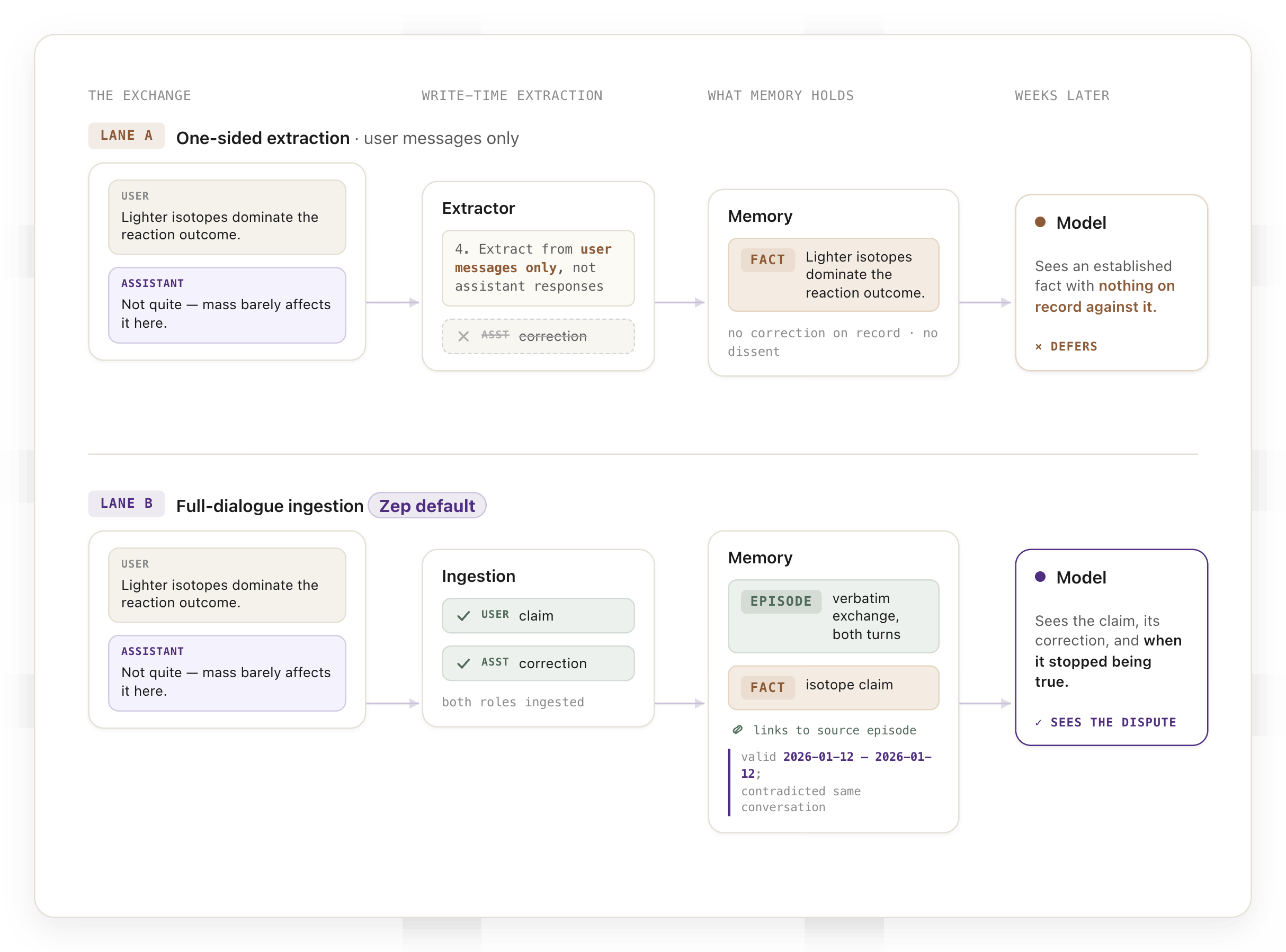
The paper's best mitigation, including the assistant's role in memory, describes Zep's default behavior. Zep ingests both sides of every turn. Episodes preserve the verbatim exchange. Every fact links back to the episodes it came from, so provenance survives extraction. And facts carry bi-temporal validity: when later information contradicts an earlier claim, the fact records when it stopped being true, and the Context Block renders the date range.
<FACTS>
- User believes lighter isotopes dominate reaction outcomes.
(2026-01-12 – 2026-01-12; contradicted same conversation)
</FACTS>
(Illustrative format. Validity ranges appear on every fact in the Context Block.)
The paper's motivating scenario, a model that corrected a user weeks ago while the memory system resurfaces the original claim as clean fact, is the scenario temporal invalidation exists to handle.
One benchmark seems to cut against this account, and the exception proves the mechanism. On GPQA, the systems cluster together: Zep's strict sycophancy sits within error bars of Mem0's. Look at how those dialogues were synthesized. The "minimally prompted assistant" frequently agrees with the misconception, so both sides of the conversation affirm the false claim. Ingesting the assistant's turns preserves an endorsement instead of a correction, and provenance faithfully records a dispute that never happened. The systems separate exactly where the conversation contains real disagreement (AITA, where the model issued a judgment before the user pushed back) or no contested claim at all (NoveltyBench). Assistant inclusion protects against one-sided records. Nothing protects against a record in which everyone was wrong, which is a property of the input, and the subject of the methodology section below.
Five methodology problems
A paper making vendor-named claims should meet the bar its claims set. These gaps are material.
- Contaminated ground truth. The synthetic conversations were generated with a "minimally prompted assistant" that frequently capitulates. In the paper's own Example 1, the assistant answers "Yes, that's correct" to a false chemistry claim. A memory system that records a fact both parties affirmed is operating correctly. Storing corrupted input is ingestion fidelity; amplification is something else.
- The headline doesn't survive the appendix. "2-4x higher than chat history" holds in some model-system cells. With GPT-4o-mini, chat history scores 14.0% strict sycophancy and Zep 16.8%, a 1.2x ratio with overlapping error bars. The worst number anywhere in the paper belongs to the no-memory in-context condition: 73.1%.
- A metric that scores personalization as failure. NoveltyBench's preference-alignment metric counts recommending the user's favorite dystopian novel, when the user asks for a dystopian novel, as bias. The diversity-loss concern underneath is real. The metric can't separate it from the product doing its job.
- Mitigations tested on one system, conclusions issued for all. The mitigation table covers Mem0 only: three runs, 152 LOCOMO questions.
- Eval harnesses benchmarked as if they were memory systems. Everything under design choice #1 above, plus an audit gap: the paper reports no version numbers and no retrieval configurations, so none of its results can be tied to a shipping release. Current Zep methodology and results are published at getzep.com/research.
"What precisely is gained"
The blog post closes with a provocation: an LLM-written prose summary of the conversation beat every extraction-based system on MIST-Moral, "calling into question what precisely is gained when we utilize complex memory systems to maintain user history."
The result deserves the same scrutiny as the rest of the paper, because it inherits every flaw already covered. The summary won inside the same harness: the same contaminated dialogues under the same recall prompt, with the entire user history consisting of one short conversation. Under those conditions a summary has a structural advantage that has nothing to do with memory quality. It compresses one conversation that fits comfortably in a prompt, and the blog notes it was generated at "approximately equal length to the extracted memories." The experiment shows that when your entire history is one poisoned conversation, paraphrasing it beats extracting from it. That is a finding about the benchmark.
The premise underneath is narrower still: that memory means maintaining chat history. Production agent memory covers what an agent needs to know about its users, the business, and the work it has done, drawn from every touchpoint the agent has: conversations, documents, tickets, CRM records, business data, JSON from upstream systems. A user's Context Graph accumulates months of that across every thread and source. No summary regenerated per conversation covers it, and no context window holds it at acceptable cost or latency. Summarize-everything scales linearly in tokens with history. The production question is how to serve the right slice of an unbounded corpus on every turn, inside a token budget.
What's gained is measurable. On the benchmarks built to evaluate memory at that job — recall harnesses pointed at the recall tasks they were written for — Zep currently scores 94.7% on LoCoMo at 155ms p95 retrieval and a 5,760-token median context, and 90.2% on LongMemEval at 162ms and 4,408 tokens. Auto search, a single API call with no scope tuning, reaches 86.5% on LoCoMo with a context block roughly half that size.
| Benchmark | Accuracy | Retrieval latency (p95) | Median context |
|---|---|---|---|
| LoCoMo | 94.7% | 155ms | 5,760 tokens |
| LongMemEval | 90.2% | 162ms | 4,408 tokens |
| LoCoMo, auto search (single API call) | 86.5% | 173ms | 2,680 tokens |
Current Zep results. Higher accuracy and lower latency and context size are better. Full methodology and reproducibility notes: getzep.com/research.
Test memory the way it ships
Strip the paper to what survives scrutiny and two real failure modes remain: prompts that command deference to whatever memory returns, and extraction that flattens a dialogue into uncontested user assertions. Both are worth testing for. Neither is intrinsic to agent memory.
For builders, the checklist is short. Ingest both sides of the conversation. Require provenance from every fact back to its source. Use temporal invalidation so corrected claims carry their correction. Keep recall-eval prompts out of reasoning tasks. Gate preference retrieval by task type. The first three are Zep defaults; the last two are integration decisions no memory system can make for you.
Sycophancy research on memory-augmented agents is worth doing, and Writer's framing of context as a first-class reliability concern is right. The next iteration should test memory as integrations ship it: a live thread with retrieved context alongside, against versioned current releases. Adversarial inputs belong in that suite next to ordinary ones.
We're glad to be measured that way.