Agent memory placement can cut your token bill up to 2x
Agent memory has to refresh every turn, but putting it in the system prompt breaks prompt caching and re-bills the whole conversation each turn. Here is the one-message fix, and the token savings it led to in an experiment.

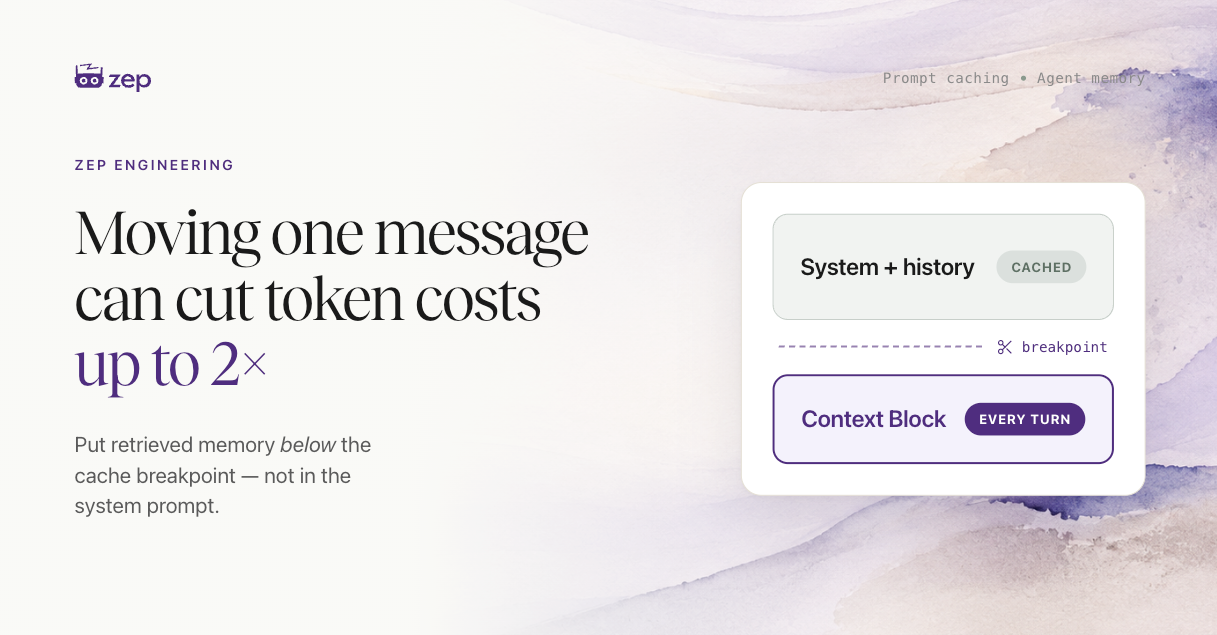
Key takeaways
- Placement is a cost decision. Agent memory is most useful when it is refreshed every turn, and where you place that fresh context in the prompt strongly affects your token cost.
- The system prompt is the expensive default. Because that block changes every turn, it breaks prompt caching: the entire conversation history below it is re-processed at full price on every turn.
- A trailing message keeps the cache. After the cache breakpoint, the system prompt and history stay unchanged and read from cache. Only the new messages and one fresh memory block are paid for in full each turn; the cached history is still paid for, at a fraction of the price.
- Up to 2x cheaper. In an experiment, this one placement change cut total token cost by up to 2x, and the savings grow the longer the conversation runs.
- It works on any provider. The technique uses a fake tool message; Claude Opus 4.8 also supports it natively with mid-conversation system messages.
Agent memory is about giving agents awareness of all the context they need to respond or to perform a task. At Zep, we have designed agent memory that adapts to every new message: when the user brings up a topic, Zep automatically assembles a Context Block of the context relevant to that topic, ready to place in the prompt. That raises a question that matters more than you might expect: where in the prompt should the Context Block go?
The obvious place is the system prompt, alongside your instructions and other standing context. That works, but it is also the most expensive option. Putting that same context in a single message at the end of the request keeps the memory just as fresh while cutting the token bill by up to 2x on a long conversation. The rest of this post explains why placement alone swings the price so much, and how to land on the cheap side.
The natural placement breaks prompt caching
It comes down to how a model bills a request. Before it can reply, the model processes the entire prompt (your system instructions and tool definitions, plus the whole conversation history) and stores an intermediate result for every token. That step is the prefill phase (as opposed to the decode phase, when the output is generated), and the stored results are its KV cache. For a long conversation, prefill is the bulk of what you pay, and it grows with the history: the more turns, the more there is to process.
Prompt caching reuses that work. Once the model has processed a prefix, its KV cache can be kept and reused, so a later request that begins with the exact same tokens skips re-processing them.
On Claude Opus 4.8, processing fresh input costs $5 per million tokens, while reading the same tokens from cache costs $0.50, a 90% discount. Writing to the cache carries a premium (on Opus 4.8, $6.25 per million tokens, or 1.25x fresh input), though you pay it once and then read cheaply on every later turn. A cache entry also expires after a set window (five minutes by default), so the savings hold when turns arrive close enough together (which can be a high fraction of the time, depending on the use case).
The rule that matters: caching matches the request prefix and holds only up to the first token that differs from the previous request.
Putting the Context Block in the system prompt is what breaks the cache. The system prompt sits at the front of the request, and the Context Block is retrieved fresh for each message, so it changes every turn. The prefix diverges right there, near the top, and everything after it — the entire conversation history — no longer matches the previous request. None of it can be served from cache, so it all gets re-processed at full input price on every single turn. History is also the part that grows: by the 50th turn you are re-processing 50 turns of dialogue just to answer the 51st.
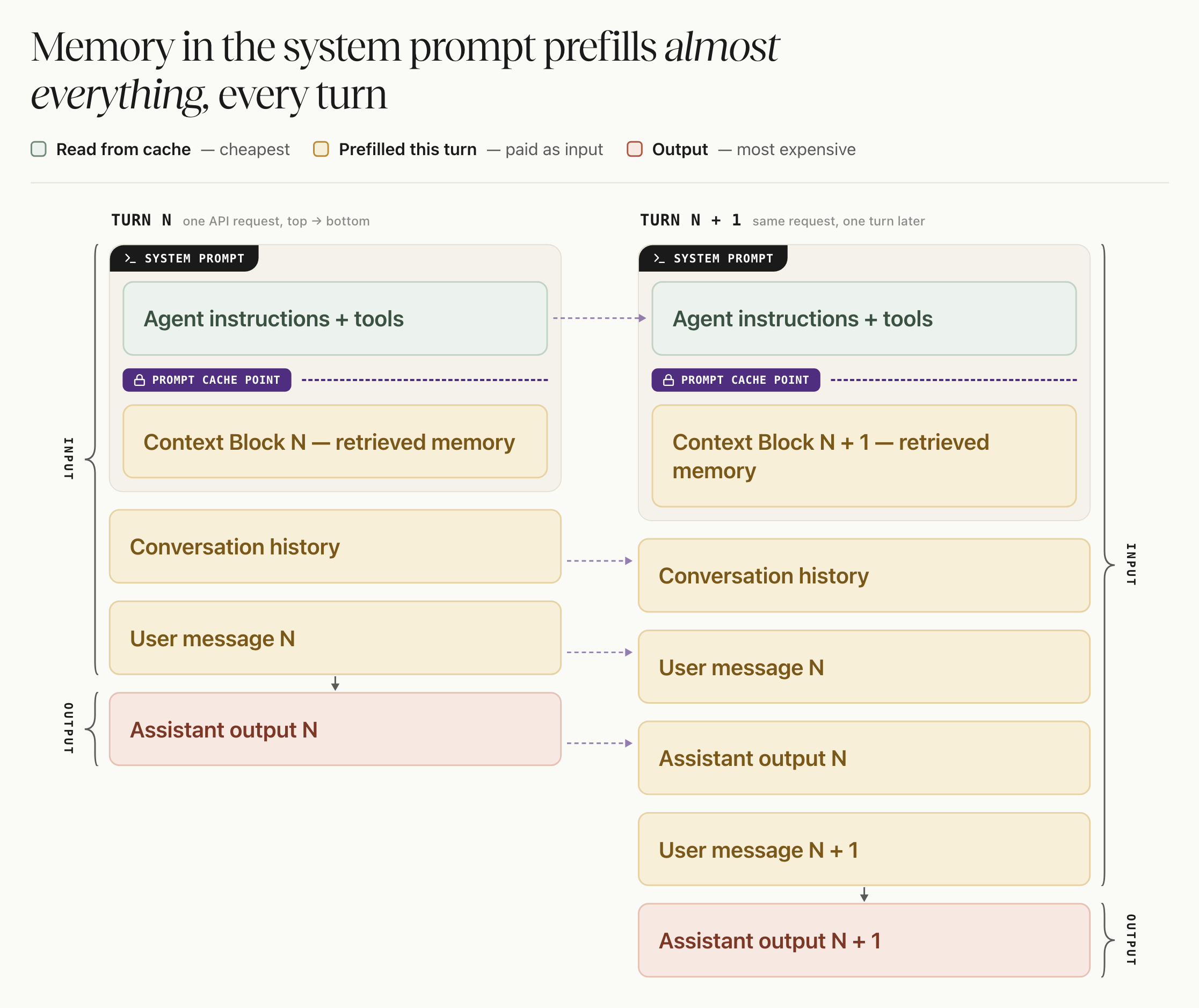
The fix: one message at the end of the request
The fix is to take the Context Block out of the system prompt and attach it as the last message in the request, after the conversation history, with the cache breakpoint set on the latest user message just before it. On most providers, this trailing message is a fake tool message: a tool-role message that carries the memory, which the Zep quickstart documents as a context message.
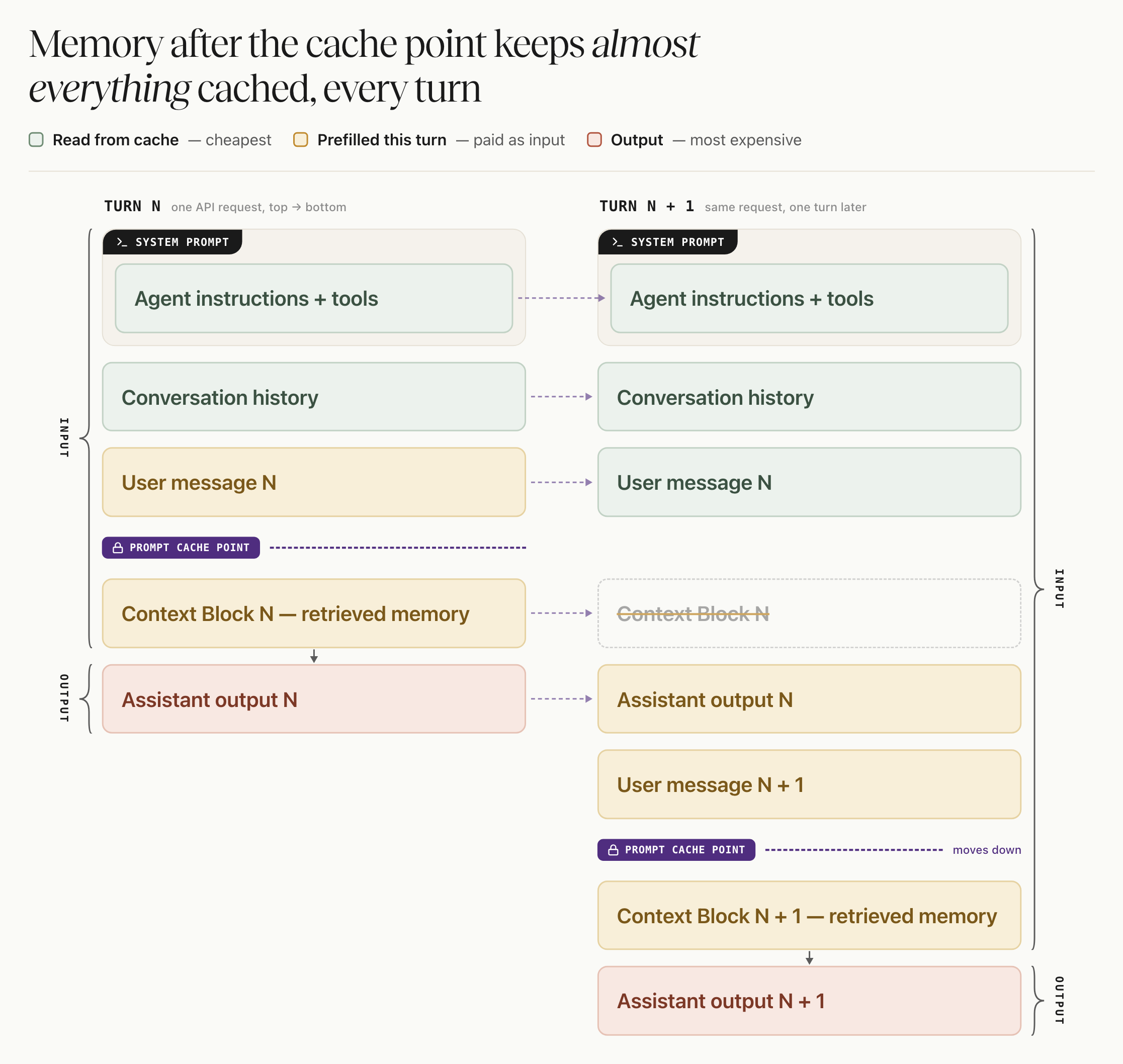
With that placement, almost everything stays still. The system prompt, the tools, and the entire conversation history up through the latest user message are identical to last turn, so the whole prefix reads from cache. The Context Block sits past the breakpoint, outside the cached region. Because it was never part of the cache, swapping it out next turn invalidates nothing.
Each new turn runs through the same three-step swap:
- The previous Context Block is dropped. It sat after the breakpoint and was never cached, so removing it costs nothing.
- The previous turn's reply and the new user message join the history, and the breakpoint moves to the new latest user message. One subtlety: the previous reply was generated right after the old Context Block, so it was never part of the cached prefix. It is processed once now, and cached from then on like the rest of the history.
- A fresh Context Block is retrieved for the new message and attached at the end.
In total, each turn pays full price for only three things: the previous turn's reply, the new user message, and one fresh Context Block. Everything else reads from cache, at a fraction of the price.
Compared to not using agent memory, you have to prefill two additional messages (the context message and the prior assistant message), but this is a constant cost that does not grow with the conversation length, and the bulk of the conversation is read from cache.

How much it saves
We ran an experiment to put a number on the cost savings. The setup is one agent with a production-scale static prompt of about 12k tokens (a persona and an operations manual, plus a dozen tool schemas), backed by a Zep user seeded with prior conversations. We replay the same scripted conversation twice: once with the Context Block in the system prompt, once as a trailing message. The Context Blocks are identical and the model's replies are identical, so the two runs are token-for-token equivalent and placement is the only variable. Costs come from the API's reported usage and Anthropic's published prices.
The trailing placement is cheaper at every length, and the gap widens as the conversation grows.
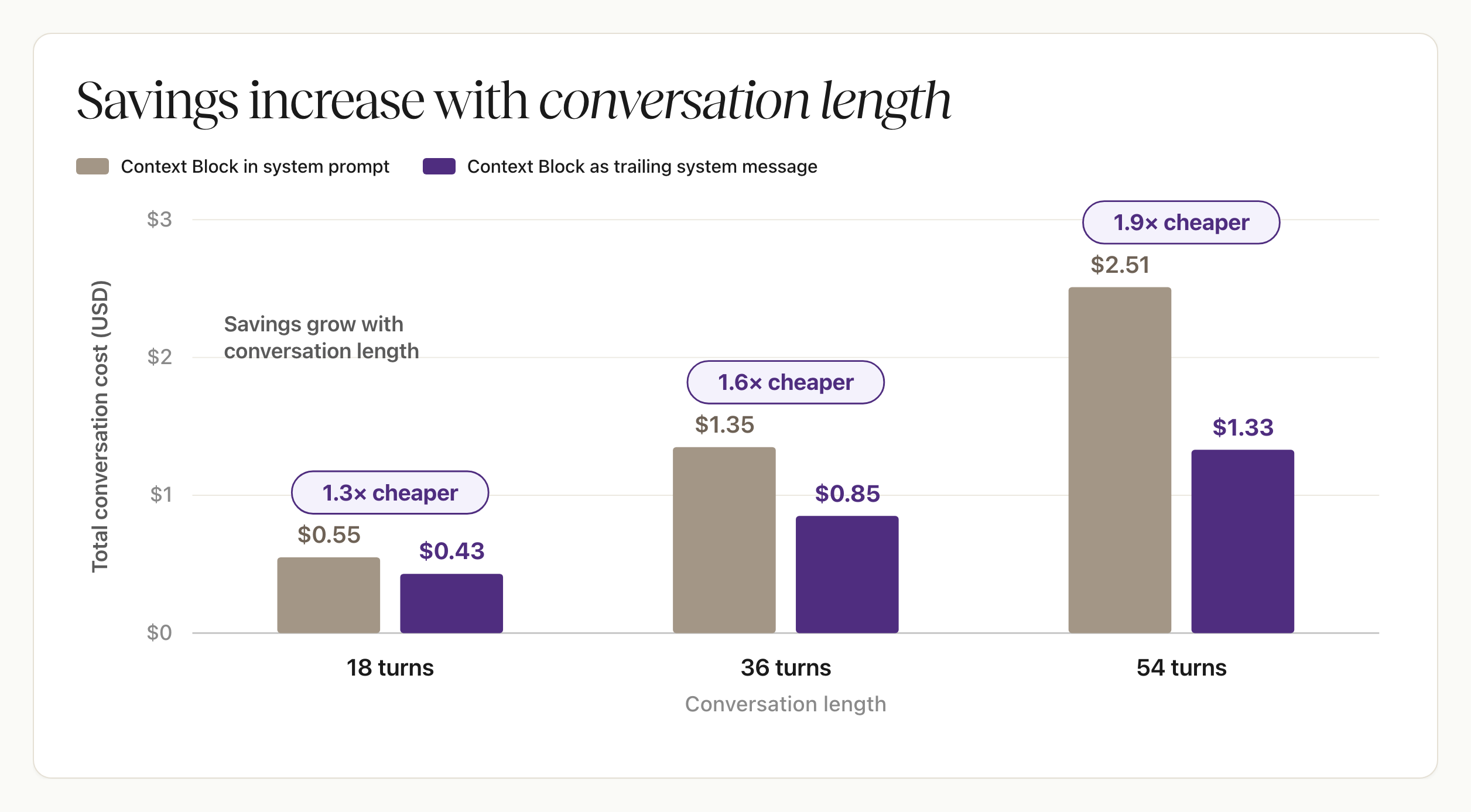
Across 18, 36, and 54 turns, total cost falls by 1.3x, 1.6x, and 1.9x: up to 2x at the lengths we tested, and still climbing. The trend matters more than any single number, because the system-prompt placement re-processes a longer history every turn, so its per-turn cost keeps rising, while the trailing placement reads that history from cache and keeps its per-turn cost roughly constant. The longer your agent runs, the more the placement is worth. The experiment code is on GitHub if you want to run it yourself.
The technique works with any LLM provider through a fake tool message, since any modern API accepts a tool-role message. Claude Opus 4.8, however, natively supports the technique with its new mid-conversation system messages, which let you append authoritative, per-turn context right after the cache breakpoint without disturbing the cached prefix. It is the same placement, now a first-class API feature.
Where to go next
If you build on Zep, it is worth checking that your implementation appends the Context Block as a fake tool message, or a mid-conversation system message on Claude Opus 4.8, and that you are taking advantage of prompt caching.
If you do not use Zep but are building production agents that need agent memory, we would love to talk.