How Zep Works: A Visual Guide to Knowledge Graphs for AI Agents

Agents don't fail because the model is bad. They fail because they don't have the right context.
Chat memory only sees conversations. Static RAG is stale and incomplete. Tool calls are slow and unpredictable. Context is scattered across systems, and your agent sees pieces, not the picture.
Zep fixes this. We've created a short video that shows exactly how Zep automatically assembles the right context from chat history, business data, and user behavior using knowledge graphs.
Three Characteristics That Matter
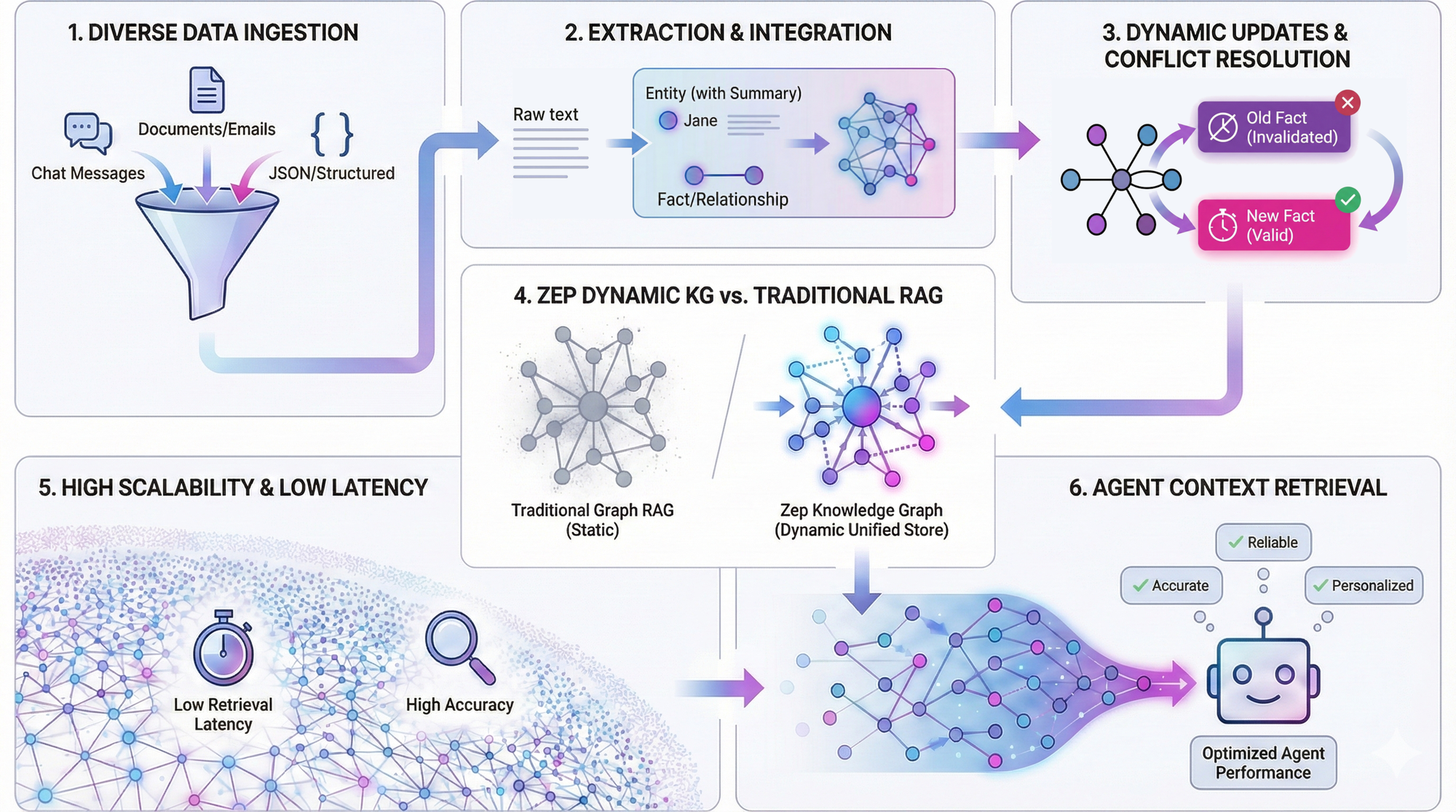
Unified: Zep ingests any kind of text data—chat messages, documents, emails, JSON, business data—and creates a single, factually consistent source of truth. No more siloed context across different data types.
Dynamic: When new information arrives, Zep automatically extracts entities, facts, and relationships, then intelligently merges them into the existing graph. If a new fact contradicts an old one (like a changed user preference), Zep marks the outdated information as invalid while preserving the history.
Long-term: Traditional graph RAG systems slow down as they grow. Zep maintains high retrieval accuracy and low latency even when knowledge graphs get very large, making it practical for agents that need to remember context from months or years ago.
Why It Matters
These three characteristics combine to give your agents superpowers: they become more accurate because they're working from a unified source of truth, more reliable because they handle conflicting information correctly, and more personalized because they can recall relevant context from any point in a user's history.
The video walks through the complete flow—from data ingestion to entity extraction to context retrieval—with visual examples that make the concepts click.
Want to learn more? Check out our documentation or join our Discord community to chat with other developers building with Zep.