Beyond Static Graphs: Engineering Evolving Relationships
Knowledge Graphs aren't adept at modeling changes in facts. This article explores the challenges we faced building time-aware Knowledge Graphs and our approaches to solving them.

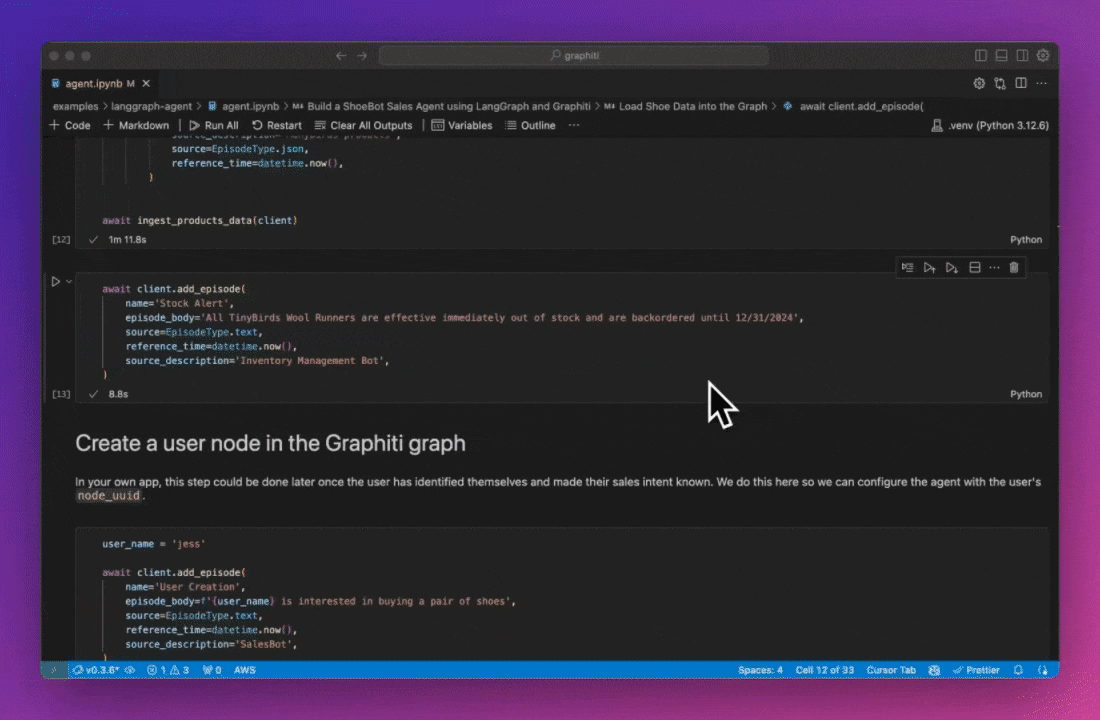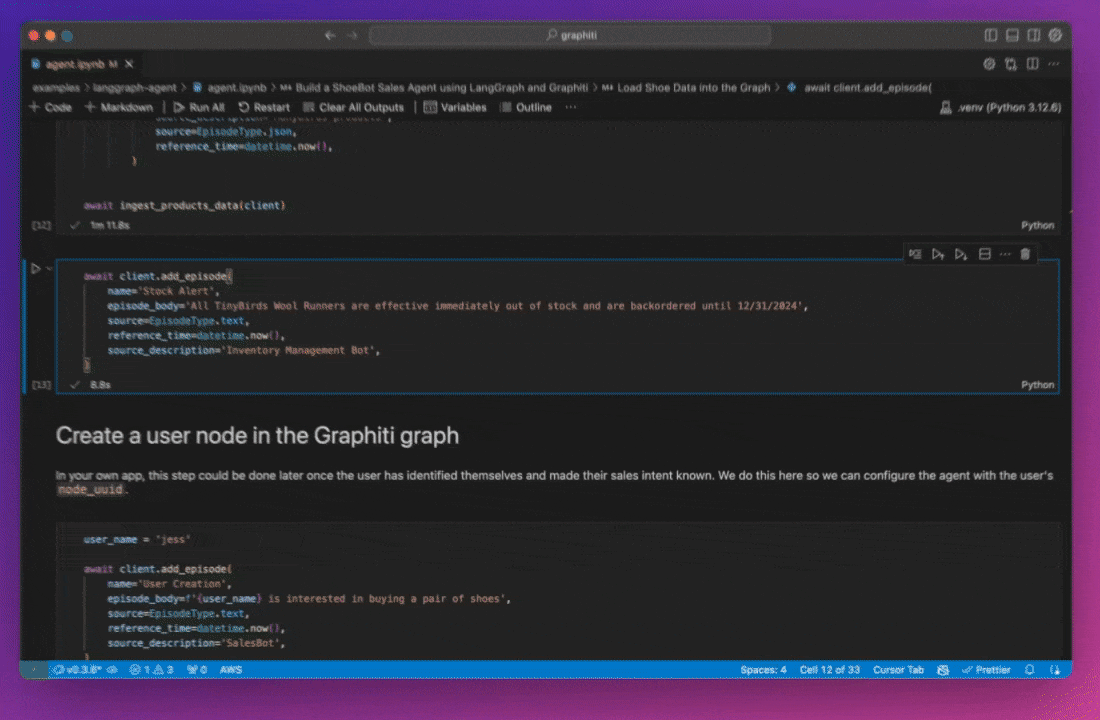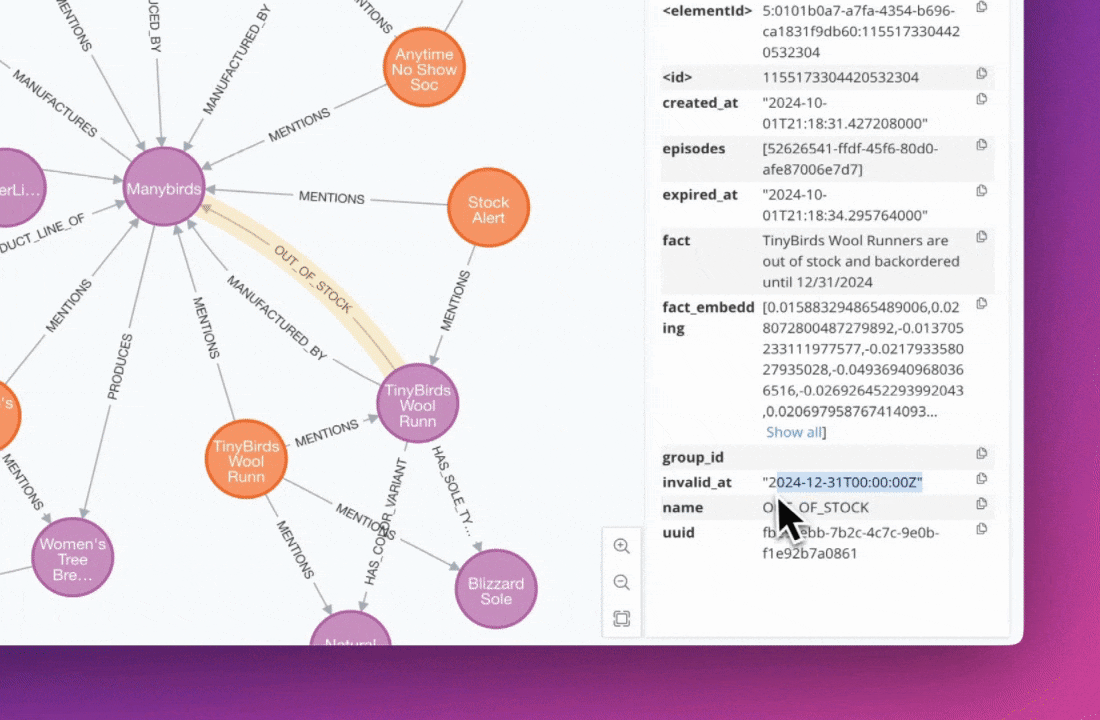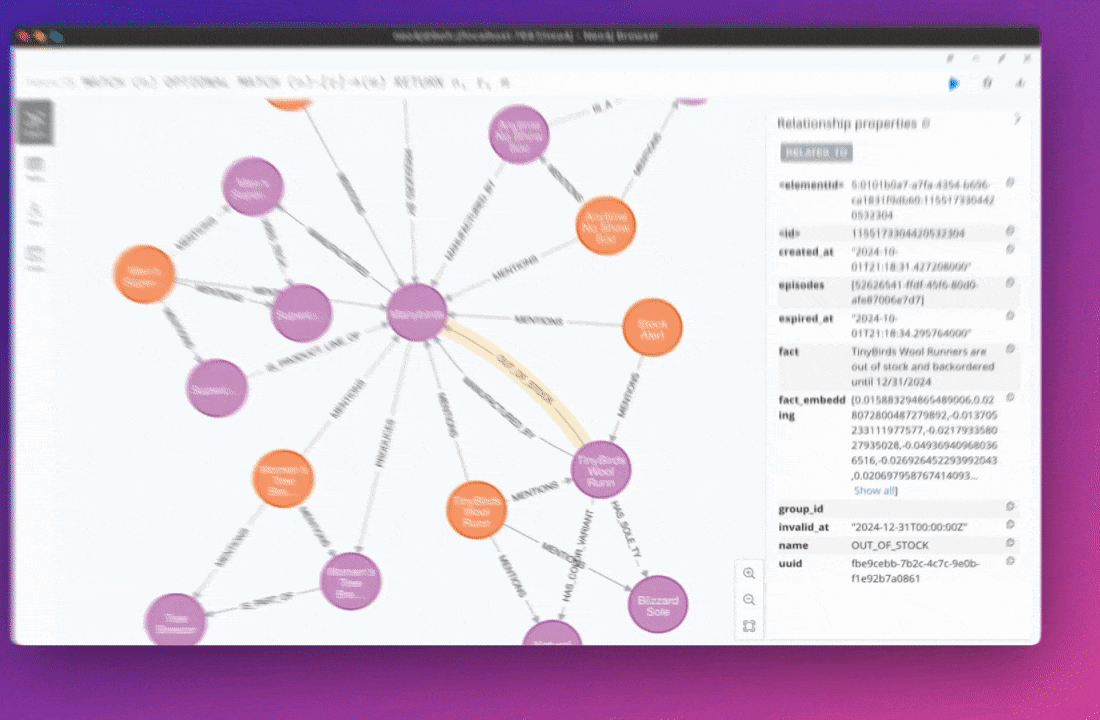
Knowledge Graphs face limitations as data complexity increases, particularly when relationships change over time and need to be modeled by the Graph. Graphiti is an open-source project designed to build and manage temporal Knowledge Graphs. This post examines Graphiti's approach to extracting temporality from source data and explores the technical hurdles and implementation details of building time-aware Knowledge Graphs.
Graphiti Fundamentals
Graphiti builds its database by ingesting episodes, which can be messages, raw text, or structured JSON data. Each episode is represented in the graph as an Episodic node type. As the system processes these episodes, it forms or updates the graph's semantic relationships (edges) and entities (nodes).
The core structure of Graphiti's knowledge representation is the Node-Edge-Node triplet, which is also represented by a fact stored as a property on the edge. This structure allows for a flexible and detailed representation of information within the graph.
What is a Temporal Knowledge Graph?
A temporal knowledge graph extends the concept of a traditional knowledge graph by incorporating time-based information. It allows you to track how relationships between entities evolve. This capability is particularly useful for applications that need to retain historical context, such as customer service records, medical histories, or financial transactions.
The Challenge of Temporal Data Extraction
Extracting temporal data is not straightforward. The complexity arises from various factors:
- Ambiguity in natural language expressions of time
- Relative time references that require context
- Inconsistencies in date formats across different sources
- The need to distinguish between different types of temporal information
To address these challenges, we incorporated a bi-temporal approach for storing time information on our edges in Graphiti. This approach allows us to track how relationships evolve in the real world and within our database.
Bi-Temporal Approach in Graphiti
In Graphiti, each relationship between entities exists in two temporal dimensions:
1. Database Transaction Time
Two fields describe this dimension:
created_at: Indicates when a relation was added to the database. This field is always present on the edge as we have access to this information during ingestion.expired_at: Indicates when a relation is no longer true (on the database level). If we find information in a new episode that negates or invalidates an existing edge, we set theexpired_atto the current timestamp. This is a nullable field on the entity edge.
2. Real World Time
Two fields describe this dimension:
valid_at: Indicates when a relation started in real-world time.invalid_at: Indicates when a relation stopped being true or valid in real-world time.
Both valid_at and invalid_at are optional fields captured by an LLM prompt during edge processing when an episode is added to Graphiti. These can be either concrete dates mentioned (e.g., "Jake: I bought a new car on June 20th, 2022") or relative times (e.g., "Jake: I bought a new car 2 years ago"). We use a reference timestamp provided with each episode to help determine the timestamp from relative time expressions.
Date Extraction Process
Graphiti handles the temporal aspect of the knowledge graph in the following manner:
- The date extraction step occurs as part of the episode processing chain.
- After extracting edges mentioned in the episode, we have a list of both new edges (facts new to our database) and existing edges (facts already in our database but mentioned again in the new episode).
- For each extracted edge, we run a date extraction prompt with the following context:
- Edge name (e.g., BOUGHT)
- Fact representing the edge (e.g., "Paul bought a new car")
- Reference timestamp of the episode
- New episode content
- Most recent episodes
We run the date extraction step for new and existing edges to ensure we don't miss any new temporal context mentioned in the episode.
Handling Existing Edges
Even if an existing edge already has temporal context attached, we still extract dates from the new episode. This allows us to update the dates if new information becomes available. For example:
Message 1 - John: I bought a new iPhone in July
Message 2 - John: Oh, scratch that, I actually bought the iPhone in August
In this case, Graphiti would correct the previously extracted valid_at to be the August timestamp.
Handling Relative Time
When dealing with relative time expressions, our date extraction prompt emphasizes capturing only the information that can be derived from the context to prevent hallucinations while still outputting a valid date. Some key instructions include:
- If only a date is mentioned without a specific time, use 00:00:00 (midnight) for that date.
- If only a year is mentioned, use January 1st of that year at 00:00:00.
- Always include the time zone offset (use Z for UTC if no specific time zone is mentioned).
You can find the full date extraction prompt here.
Using Extracted Dates to Invalidate Edges
As we process episodes, we perform date extraction and invalidation concurrently. This approach helps identify edges that contradict or conflict with newly extracted information. We make an LLM call for each new edge using an invalidation prompt, providing existing similar edges as context.
After the invalidation process, each new edge may have a list of existing edges that conflict with it.
Example:
# Existing edge:
existing_edge = "Maria -> works_as -> junior manager"
# New episode:
new_episode = "Maria: I just got promoted and work as a senior manager now"
# Newly extracted edge:
newly_extracted_edge = "Maria -> works_as -> senior manager"
# Existing edge in conflict:
edges_to_invalidate = [
"Maria -> works_as -> junior manager"
]
We mark conflicting edges as 'expired' by setting the expired_at field on the Edge property. We also regenerate the fact stored on the invalidated edge to reflect updated knowledge.
For example,
Maria works as a junior manager
becomes
Maria used to work as a junior manager, until her promotion to a senior manager.
This approach allows us to retrieve a cohesive narrative of events when searching Graphiti.
While the approach above works well for chronological episodic flow, episodes are often not added to Graphiti chronologically. Consider this example:
# Reference timestamp: Sep 30 2024
Josh: I divorced Jane last month # episode 1
Josh: I married Jane in August 2005 # episode 2In this case, episodes are not added in their real-world chronological order. We use valid_at dates to align edges on the world timeline to address this.
We extract a Josh -> DIVORCED_FROM -> Jane Edge from the first episode with a valid_at field set to August 1st 2024.
From the second episode, we extract a Josh -> MARRIED_TO -> Jane edge with a valid_at field set to August 1st 2005.
When running the invalidation prompt for the MARRIED_TO edge, we determine it conflicts with the existing DIVORCED_FROM edge. To decide which edge to mark as expired, we sort them by their valid_at dates extracted from the relative time mentioned in the episodes. We then invalidate the edge that occurred earlier in the real world.
Consequently, we mark the Josh -> MARRIED_TO -> Jane edge as expired in our database and update the fact stored on the edge accordingly.
Storing and Querying Temporal Data
Once date extraction and other edge processing steps are complete, we save the information to the graph database. The created_at, expired_at, valid_at, and invalid_at dates will be available on the edges when searching Graphiti. We plan to add temporal filtering capabilities to the search API soon.
Conclusion
Temporal knowledge graphs offer a powerful way to represent and query time-sensitive information. Graphiti's bi-temporal approach provides a robust framework for handling complex temporal data in knowledge graphs. We encourage you to experiment with ingesting temporally rich episodes into Graphiti and share your experiences with us on our Discord channel. If you encounter any issues, please open an issue on the Graphiti repository and let us know.
By leveraging Graphiti's temporal capabilities, you can build more sophisticated and context-aware knowledge graph applications that accurately represent the evolution of relationships over time.
If this post piques your interest, please check out Graphiti's GitHub repo.