Foundations of LLM App Building in TypeScript
Learn how to build three foundational LLM apps using TypeScript, LangChain.js, and Zep.


Python gets much of the love in the LLM space. However, most web apps are built using TypeScript, JavaScript, and related technologies. Zep has first-class support for TypeScript and JavaScript, and this article explores using Zep and LangChain.js to build the foundation for various types of LLM apps.
Zep's long-term memory store makes it simple for developers to add relevant documents, chat history memory & rich user data to their prompts and without having to manage multiple pieces of infrastructure. Zep also automatically embeds chat history and documents, reducing reliance on 3rd-party embedding APIs.
An overview of the LangChain features we'll use
We're going to build the foundations for three types of applications, all using LangChain's ZepMemory and ZepVectorStore classes.
- A simple conversational bot using a
ConversationChain. We'll use this to demonstrate the ability to recall past conversations. - A Retrieval Augmented Generation app using a
ConversationalRetrievalQAChain. We'll demonstrate how to populate Zep's VectorStore with several books, and ask the LLM questions about the books. - Lastly, we'll build a REACT-type agent that has access to two tools. The first, a
peopleRetrievertool, provides search access to historical chat messages but filtered by entity for people's names. The second, thebookSearchtool, provides search access over our book collection.
We'll use LangChain's new LangSmith platform for observability, providing insight into what our chains and agent are doing under the hood.
A simple conversational bot recalling past conversations
This somewhat trivial example demonstrates preloading historical conversation into Zep and passing an instance of ZepMemory to the chain.
Let's start off by initializing Zep in our app and creating a sessionId, a unique key representing the user or a user's chat session. We'll then load some test data into the chat history for this session.
// Create a new ZepClient instance
const client = await ZepClient.init(ZEP_API_URL, ZEP_API_KEY);
// Create a session ID for our conversation. This ID could represent our user, or a
// conversation thread with a user. i.e. You can map multiple sessions to a single user
// in your data model.
const sessionId = randomUUID();
// add the sample chat history to the Zep memory
const messages = history.map(
({ role, content }: { role: string; content: string }) =>
new Message({ role, content }),
);
const zepMemory = new Memory({ messages });
await client.memory.addMemory(sessionId, zepMemory);
Let's now create an instance of ZepMemory initialized for the above session, and create our chain. We'll ask the LLM what we've discussed so far, giving it the opportunity review the chat history provided by Zep.
// Create a new ChatOpenAI model instance. We'll use this for both oru chain and agent.
const model = new ChatOpenAI({
modelName: "gpt-3.5-turbo",
temperature: 0,
});
// Let's create a new ZepMemory instance with very simple configuration.
// We'll use this in our first chain to demonstrate the basics by recalling the
// chat history we've just added to Zep.
const memorySimple = new ZepMemory({
sessionId,
baseURL: ZEP_API_URL,
apiKey: ZEP_API_KEY,
});
// Let's start with a simple chain and ask the LLM what we've discussed so far.
const conversationChain = new ConversationChain({
llm: model,
memory: memorySimple,
});
const res1 = await conversationChain.run("What have we discussed so far?");
console.log(res1);Thanks to LangSmith, we have visibility into the data sent to the LLM. You'll note below that Zep has automatically summarized the long chat history and provided it to our chain as a system message. Zep does this asynchronously on the server in order to avoid impacting the user experience.
LangSmith has the nifty ability to share traces and you can find the trace for this chain here.
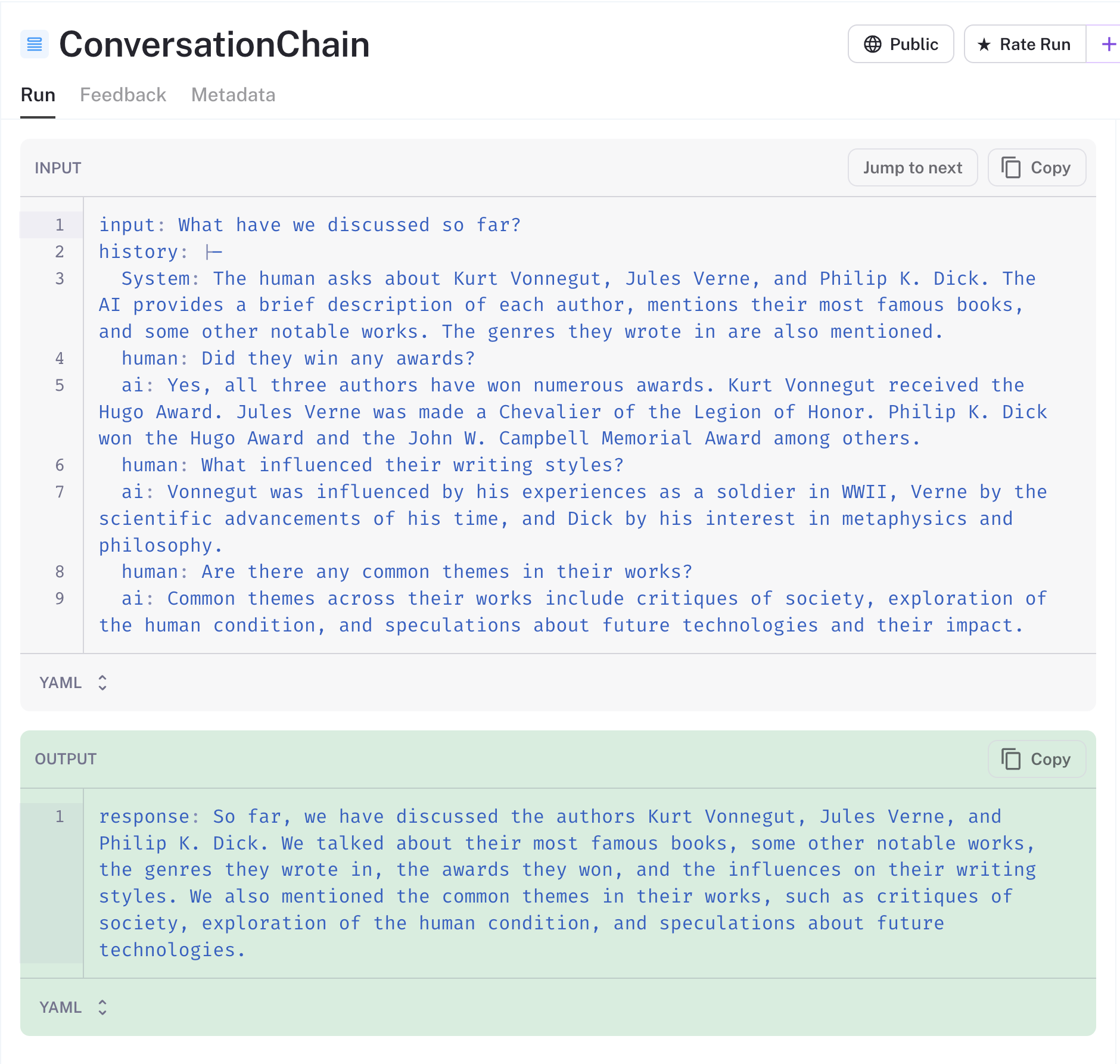
For each subsequent turn of the conversation, LangChain will persist AI and human messages to Zep. These messages will be automatically added to later prompts.
Alongside summarization, Zep also enriches memories with named entities, an intent analysis, and token counts. We'll use some of this metadata later when we build our agent.
{
"uuid": "d02a90a7-0981-43ae-92bf-95e448f6fff4",
"created_at": "2023-08-17T04:11:43.520994Z",
"role": "AI",
"content": "So far, we have discussed the authors Kurt Vonnegut, Jules Verne, and Philip K. Dick. We talked about their most famous books, some other notable works, the genres they wrote in, the awards they won, and the influences on their writing styles. We also mentioned the common themes in their works, such as critiques of society, exploration of the human condition, and speculations about future technologies.",
"token_count": 88,
"metadata": {
"system": {
"entities": [
{
"Label": "PERSON",
"Matches": [
{
"End": 51,
"Start": 38,
"Text": "Kurt Vonnegut"
}
],
"Name": "Kurt Vonnegut"
},
{
"Label": "PERSON",
"Matches": [
{
"End": 64,
"Start": 53,
"Text": "Jules Verne"
}
],
"Name": "Jules Verne"
},
{
"Label": "PERSON",
"Matches": [
{
"End": 84,
"Start": 70,
"Text": "Philip K. Dick"
}
],
"Name": "Philip K. Dick"
}
]
}
}
}
Building a Q&A over Docs / RAG-type app
Next, we'll use Zep's VectorStore to support a ConversationalRetrievalQAChain searching over a Zep document Collection. We've downloaded three public domain scifi books and will be using these for our demo.
How we approach chunking can significantly effect the performance of our app. Since we have multiple books and will be chunking each of these, we've included the file name as a prefix to each chunk. This ensures the LLM can relate a chunk to its source.
async function loadDocs(path: string): Promise<Document[]> {
return new DirectoryLoader(path, {
".txt": (path) => new TextLoader(path),
}).load();
}
async function loadDocsIntoVectorStore(
config: IZepConfig,
): Promise<ZepVectorStore> {
const docs = await loadDocs("./books");
console.log(`Loaded ${docs.length} documents`);
// Split the documents into chunks
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
separators: ["\n\n", "\n", " ", "", "\r", "\r\n"], // add carriage returns to the list of separators
});
// Split the documents into chunks. We also add the source of the document as a header to each chunk.
const chunks = (
await Promise.all(
docs.map((doc) =>
splitter.splitDocuments([doc], {
chunkHeader: doc.metadata.source
? "SOURCE: " + doc.metadata.source.split("/").pop() + "\n\n"
: "",
appendChunkOverlapHeader: true,
}),
),
)
).flat();
return ZepVectorStore.fromDocuments(chunks, new FakeEmbeddings(), config);
}We're creating a new Zep Collection, and so the config we pass into the loadDocsIntoStore function includes mandatory embeddingDimensions and isAutoEmbedded fields. The first specifies the width of the vectors generated by the embedding model we'll use, and the second tells Zep whether it should embed the documents for us. We can alternatively pass in embedding vectors.
const config: IZepConfig = {
apiUrl: ZEP_API_URL,
apiKey: ZEP_API_KEY,
collectionName: ZEP_COLLECTION_NAME,
embeddingDimensions: 768, // Set to the width of the model configured in Zep. Use 1536 for OpenAI
isAutoEmbedded: true,
};Let's populate our collection with documents and wait for Zep to embed them. Zep Collections have a status field that we can poll to determine whether all present documents have been embedded.
// Create a new ZepVectorStore instance and load a document collection into it
const vectorStore = await loadDocsIntoVectorStore(ZEP_COLLECTION_CONFIG);
// Wait for the ZepVectorStore to finish embedding the documents
console.log("Waiting for Zep to finish embedding documents...");
while (true) {
const c = await client.document.getCollection(ZEP_COLLECTION_NAME);
console.log(
`Embedding status: ${c.document_embedded_count}/${c.document_count} documents embedded`,
);
await new Promise((resolve) => setTimeout(resolve, 1000));
if (c.status === "ready") {
break;
}
}Next, we'll configure our memory and chain classes and question the LLM about the books. We've configured the ZepMemory with a memoryKey and other fields. These need to be aligned with the prompts a chain uses and are dependent on the chain class.
// Let's create a new ZepMemory instance. This will be used to store the current state of the conversation.
// Zep will also auto-summarize and enrich memories for you.
const memory = new ZepMemory({
sessionId,
baseURL: ZEP_API_URL,
apiKey: ZEP_API_KEY,
memoryKey: "chat_history",
inputKey: "question", // The key for the input to the chain
outputKey: "text", // The key for the final conversational output of the chain
});
// Create a new ConversationalRetrievalQAChain instance
// Initialize the chain with the model, the vector store, and the memory
// We'll configure the VectorStore's Retriever to use Maximal Marginal Relevance reranking.
// This will re-rank the search results to ensure that the results are diverse.
const chain = ConversationalRetrievalQAChain.fromLLM(
model,
vectorStore.asRetriever({
searchType: "mmr",
k: 4,
}),
{ memory: memory },
);In the code above, we're passing in the ZepVectorStore class as a LangChain Retriever. Under the hood, Zep uses cosine similarity normalized to [0,1] to order search results. Here, we're configuring the Zep retriever to use Maximal Marginal Relevance to re-rank search results for diversity. This is useful for RAG apps but domain-dependent, and you should explore how helpful it is for your use case.
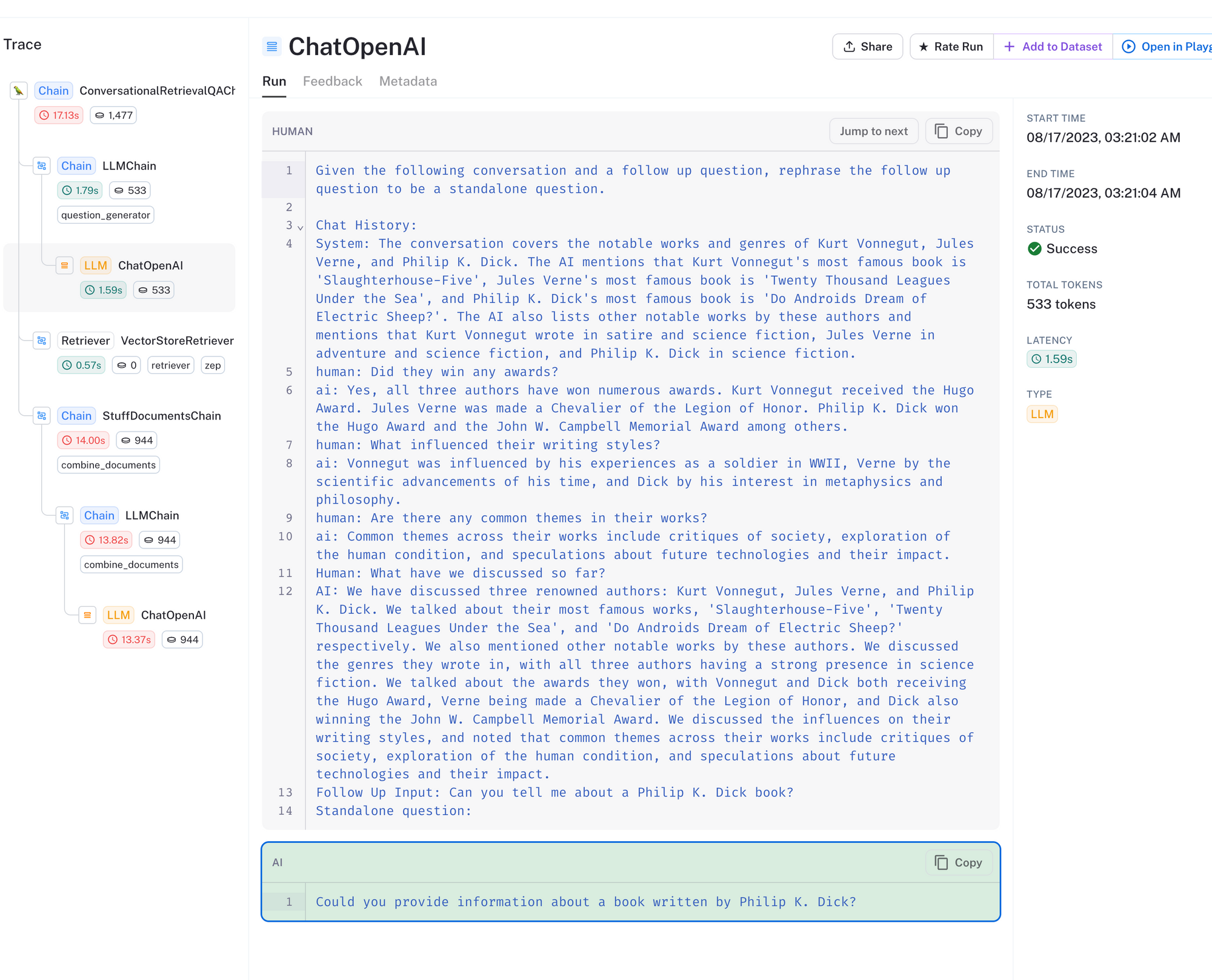
The trace for a call to the chain is above. With the ConversationalRetrievalQAChain, multiple calls are made to the LLM. First, depicted above, the LLM is provided with the user's question and the chat history and is asked to rephrase the question given this context. The rephrased question is then used to search over the document collection.
This approach is helpful when a user's question alone does not convey enough context to search the vector database.
I mentioned above how a thoughtful approach to chunking is essential to how well our app works. Well, so is data preparation. In looking at the search results from the vector store, I see that the first result is the Project Gutenberg preface to the book, as it is close in the vector space to our book-related query.
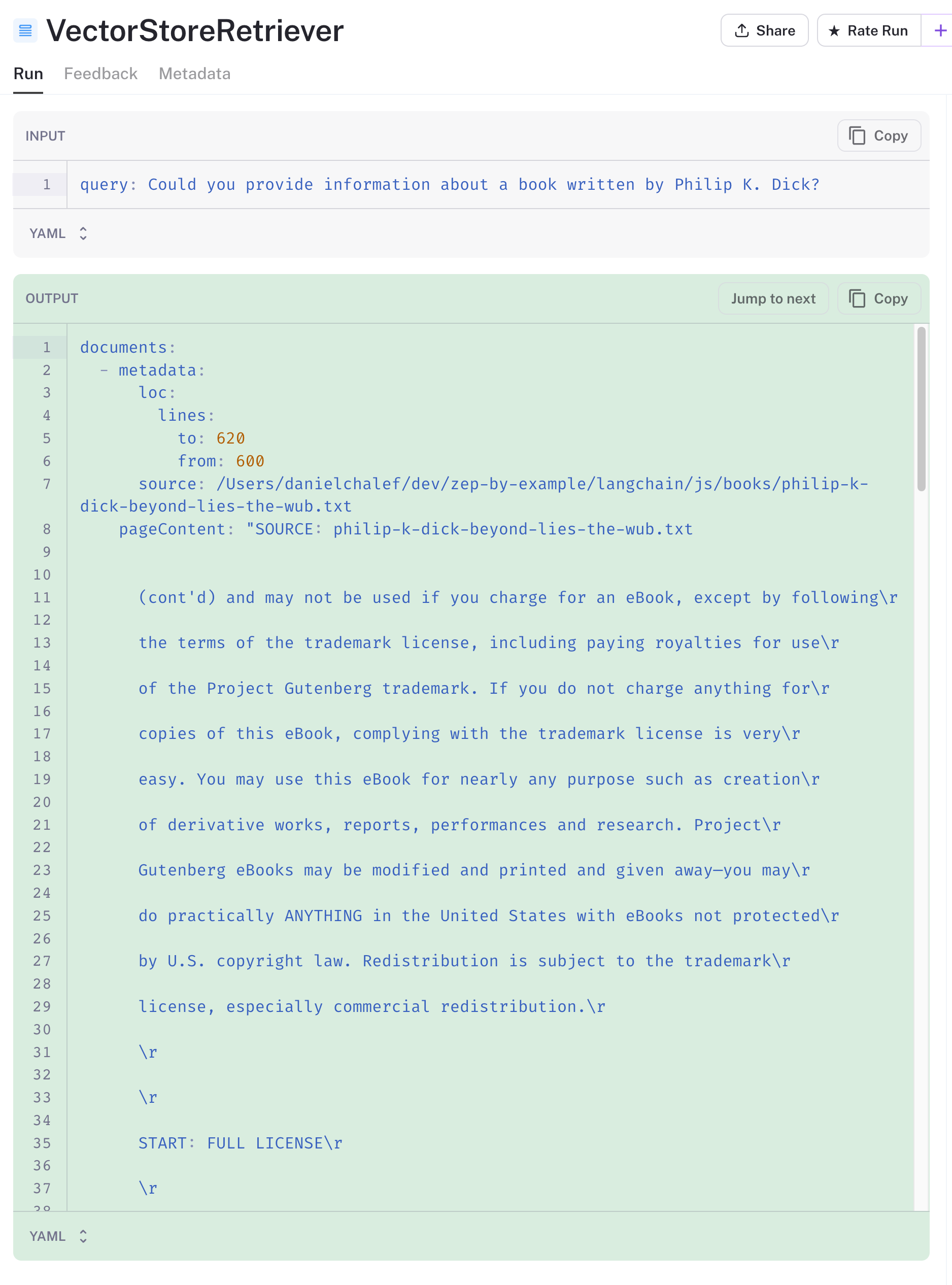
We'd probably want to remove the preface when loading the files and before chunking to improve our results. The other three results are, however, relevant.
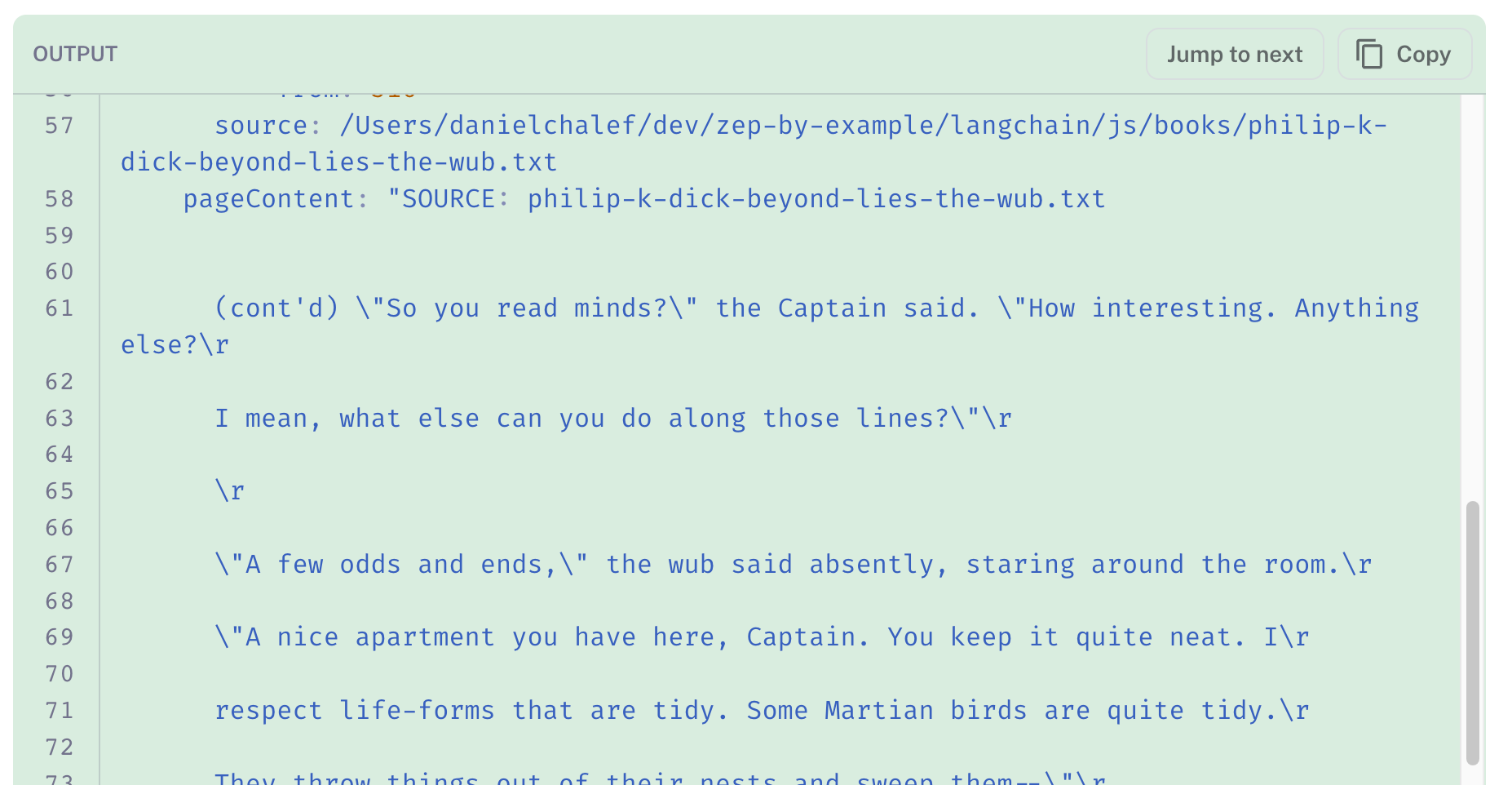
Next, the search results are added to the prompt, along with the rephrased question. The LLM's response is highlighted in green below. It does a pretty good job of making sense of the document chunks we've provided it. The "source" header we added to each chunk has ensured that results relevant to Philip K. Dick are returned.
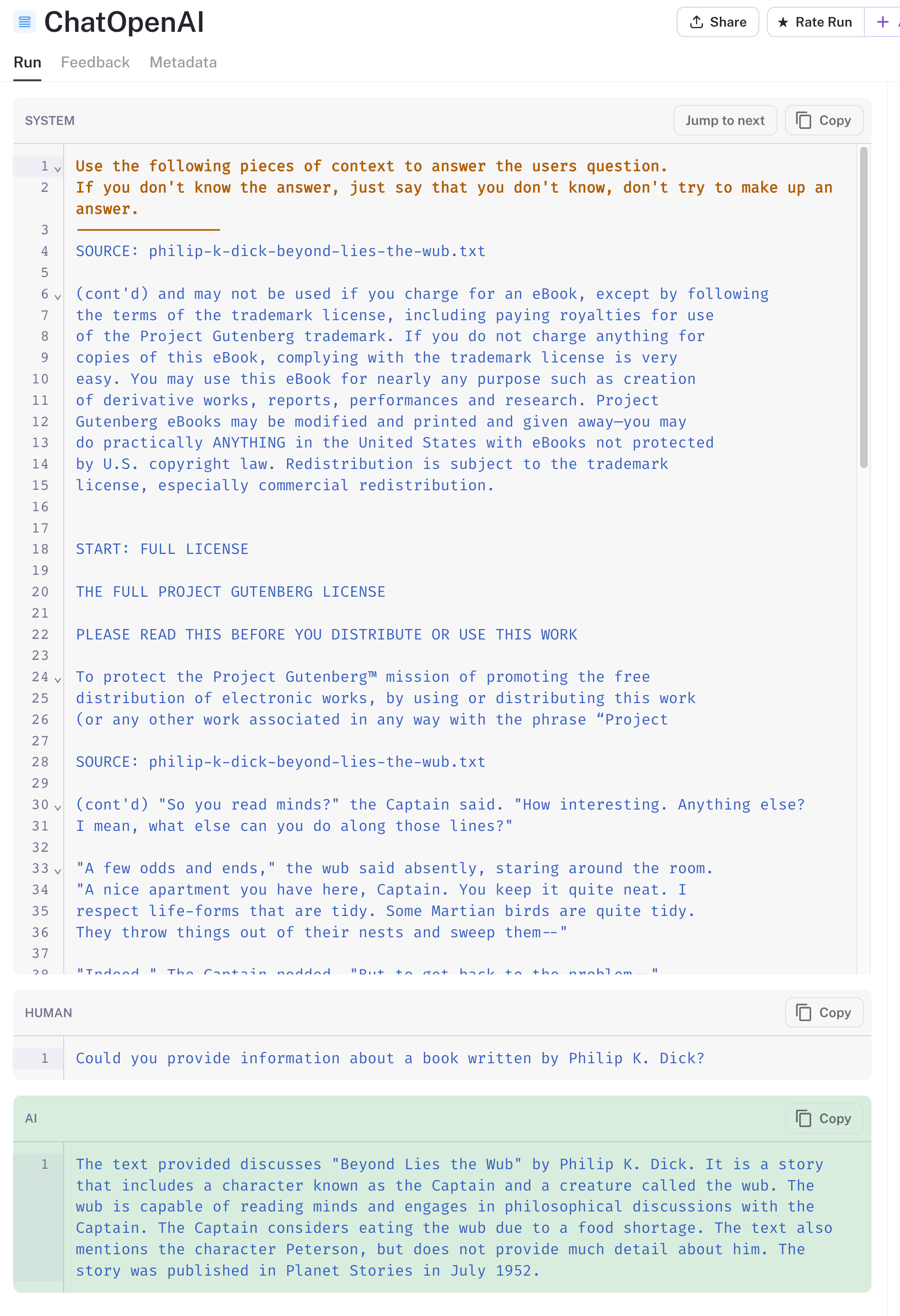
There are alternative approaches to summarizing and refining search results before populating them into a prompt. These do come at the cost of additional LLM calls, so it's worth exploring the value trade-off for your app.
Building a REACT-type agent with Zep Memory Retrieval and Search as Tools
The last type of app we'll build is an agent that uses Zep's conversational history and vector store as tools. We'll take a quick look at the set up below, but will spend time on the tools themselves.
We're using the initializeAgentExecutorWithOptions helper function to initialize the agent, passing in our tool list and LLM. Passing in a ZepMemory class is also possible, but we'll keep it simple for this demonstration.
Each tool has a description that the LLM uses to determine which tool will most likely help it with its task. Note that the agent and tool setup below is fairly primitive. You can build far more sophisticated ones using Zod and OpenAI Functions.
// Let's build an agent!
const zepMemoryRetriever = await new ZepRetriever({
url: ZEP_API_URL,
apiKey: ZEP_API_KEY,
sessionId: sessionId,
});
// Create some tools.
const tools = [
new DynamicTool({
name: "peopleRetriever",
description: `call this if you want to search for authors, characters, or people we may have discussed in the
past. input should be a search string`,
func: async (query) =>
await getPeopleFromMemoryTool(query, zepMemoryRetriever),
}),
new DynamicTool({
name: "bookSearch",
description:
"call this if to search for passages in sci-fi books. input should be a search string",
func: async (query) => await getBookSearchTool(query, vectorStore),
}),
];
const executor = await initializeAgentExecutorWithOptions(tools, model, {
agentType: "zero-shot-react-description",
});Zep has a special LangChain Retriever, the aptly named ZepRetriever, for searching over a session's chat history. We're using this above in our first tool, the peopleRetriever. As the description implies, this tool searches over historical chat messages for a person. The tool also filters chat message results using Zep's entity metadata for PERSON entities.
async function getPeopleFromMemoryTool(
query: string,
retriever: ZepRetriever,
): Promise<string> {
return retriever
.getRelevantDocuments(query, {
metadata: {
where: { jsonpath: '$.system.entities[*] ? (@.Label == "PERSON")' },
},
})
.then((docs) => {
const filteredDocs = docs.filter((doc) => doc.metadata.dist >= 0.8);
return (
filteredDocs.length > 0
? filteredDocs.map((doc) => doc.pageContent)
: ["No results"]
).join("\n\n");
});
}The function also filters for a cosine similarity above 0.8 to ensure that irrelevant chat messages are not returned to the LLM.
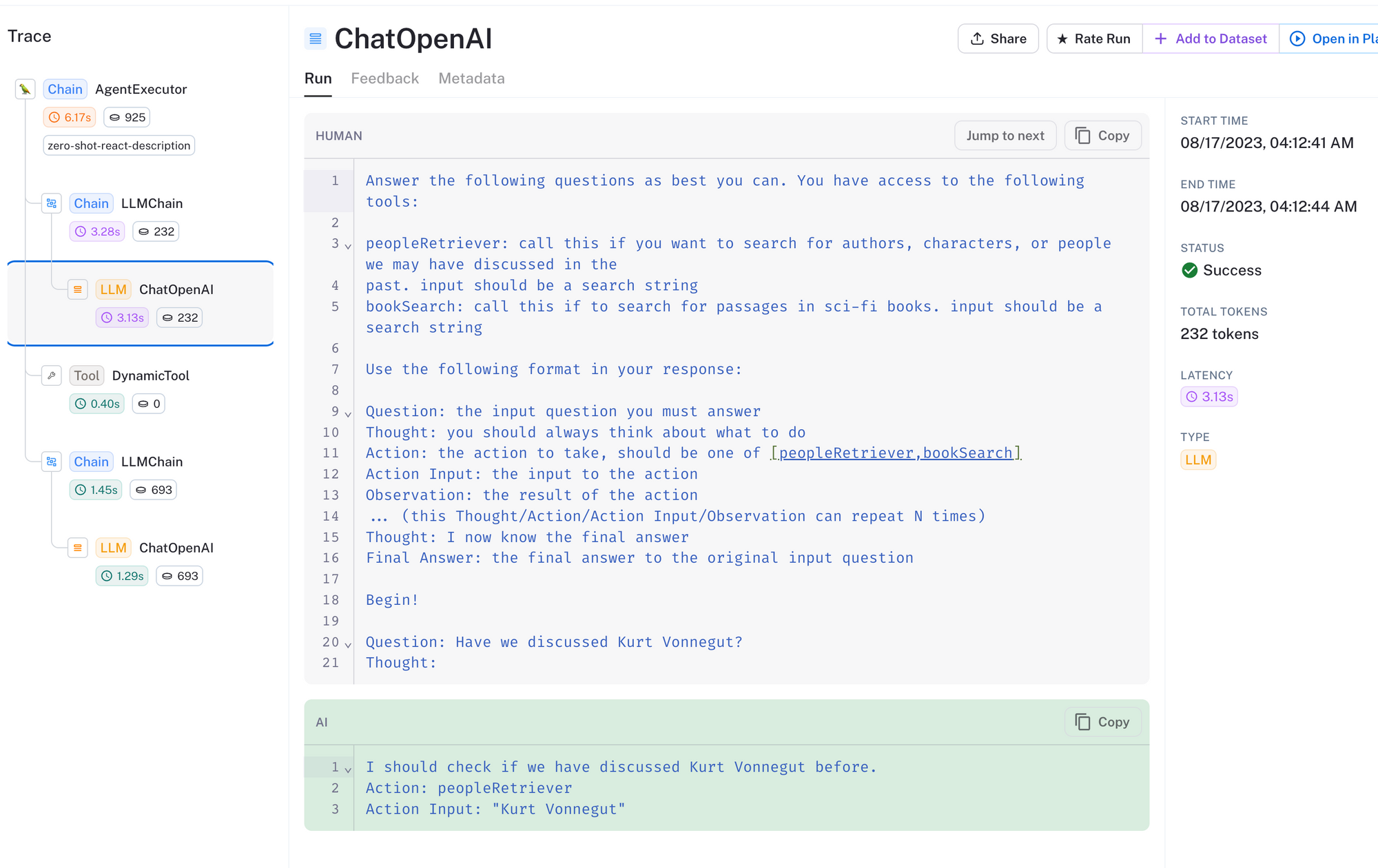
In the trace above, we can see that we've asked the agent whether we've previously discussed Kurt Vonnegut. The agent has correctly determined that it should use the peopleRetriever tool with input Kurt Vonnegut.
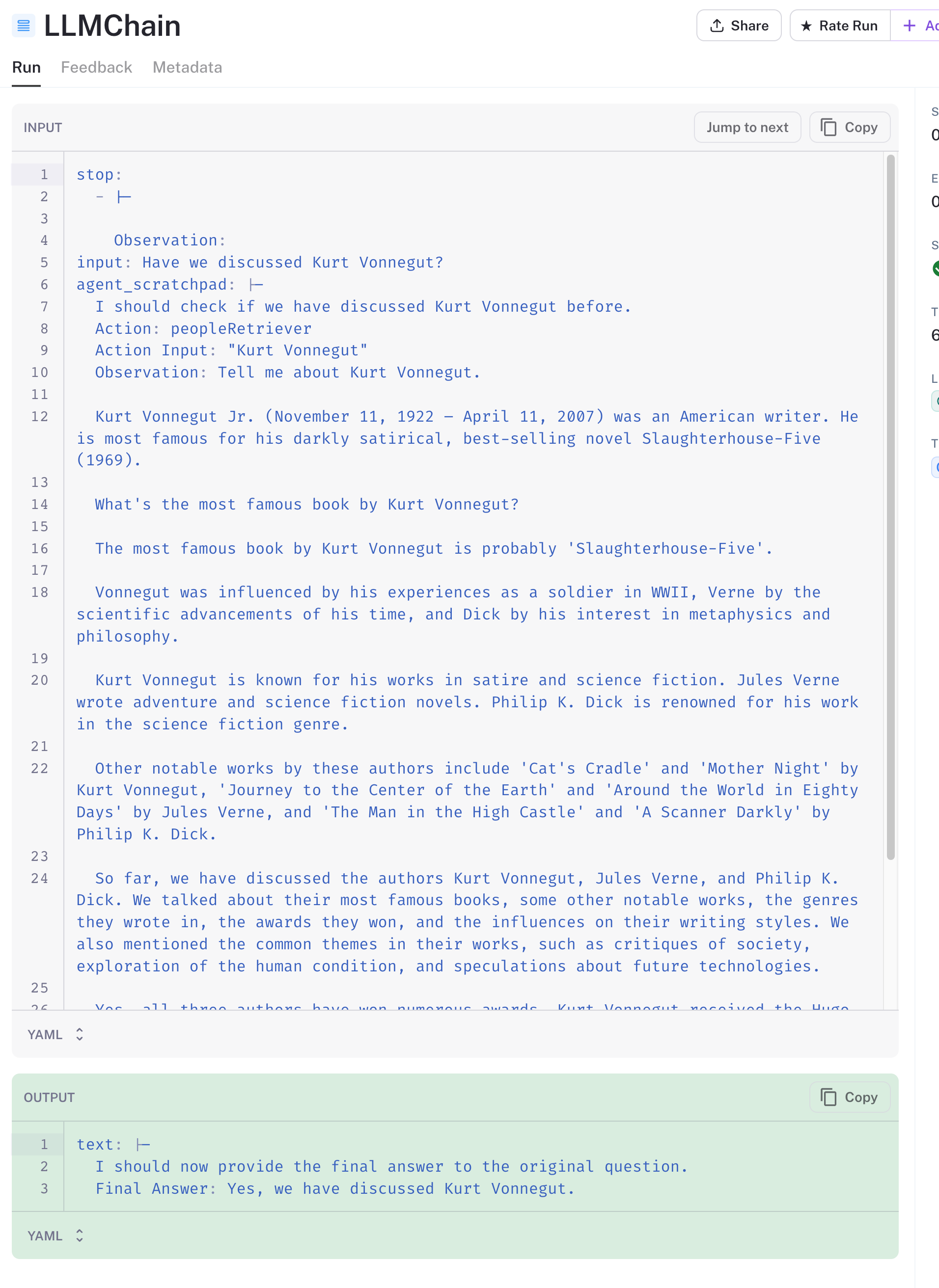
Next, the search results are returned from the tool, passed to the LLM, and it has determined that we have indeed mentioned Kurt Vonnegut in our prior conversations.
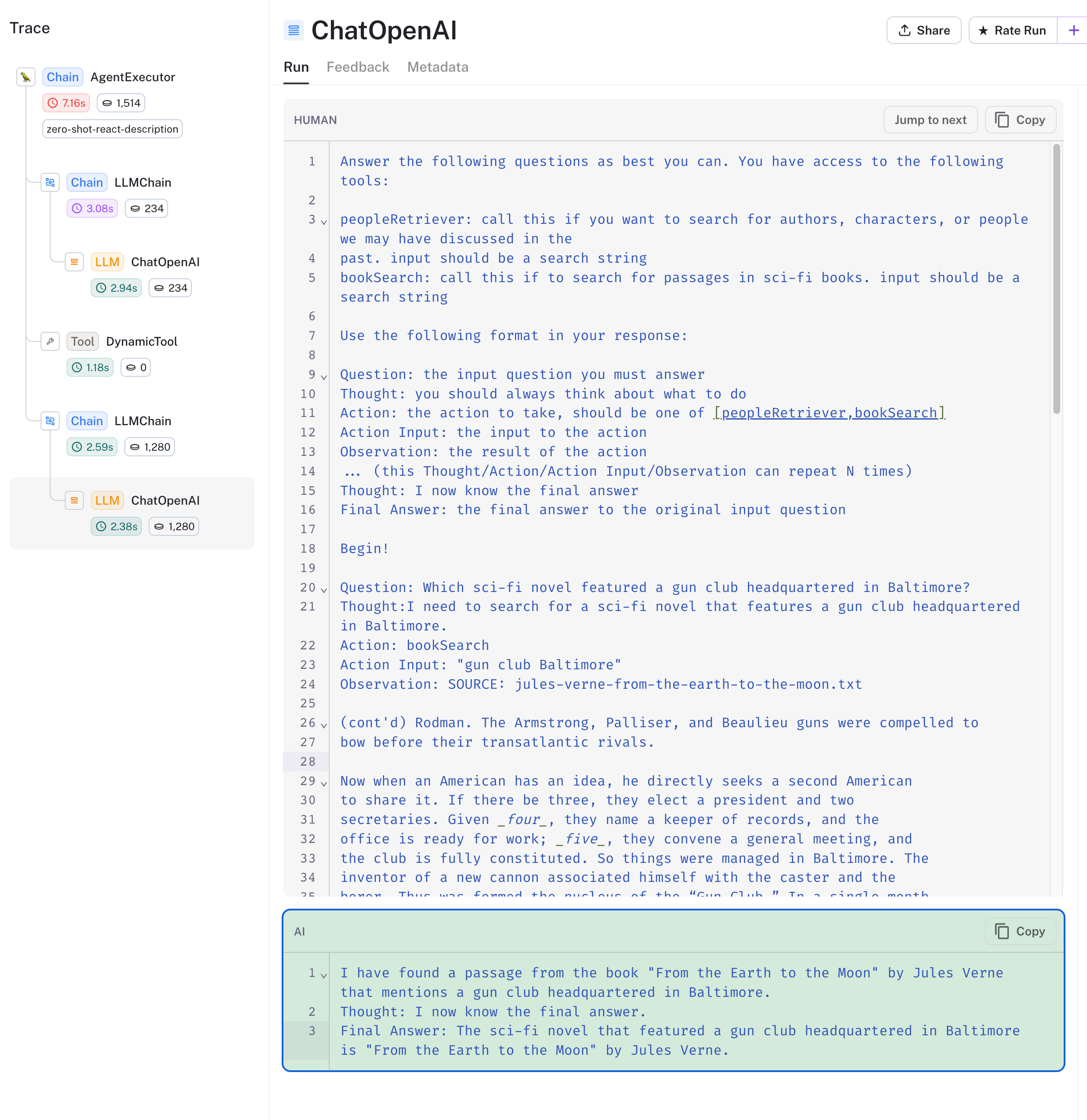
Finally, let's take a look at the agent's use of the bookSearch tool. We've asked it the following question: Which sci-fi novel featured a gun club headquartered in Baltimore?
Viewing the trace below, we see the agent chose the correct tool and searched the book collection for gun club Baltimore. The vector database returned book chunks relevant to the query, and the agent responds with From the Earth to the Moon by Jules Verne.
Summing it up
We've explored how to build three foundational LLM app types using LangChain.js and Zep, and, using LangSmith, took a look under the hood as to how things worked.
As mentioned above, the chains, agents, and tools we used are quite primitive. The LangChain docs are worth exploring as you consider how to solve different problems when building your app. You'll see most value from Zep's features, including message metadata, when you start to customize or build your own agents and tools.
Next Steps
- Sign up for the LangSmith beta
- Get setup with Zep using the Quick Start Guide.