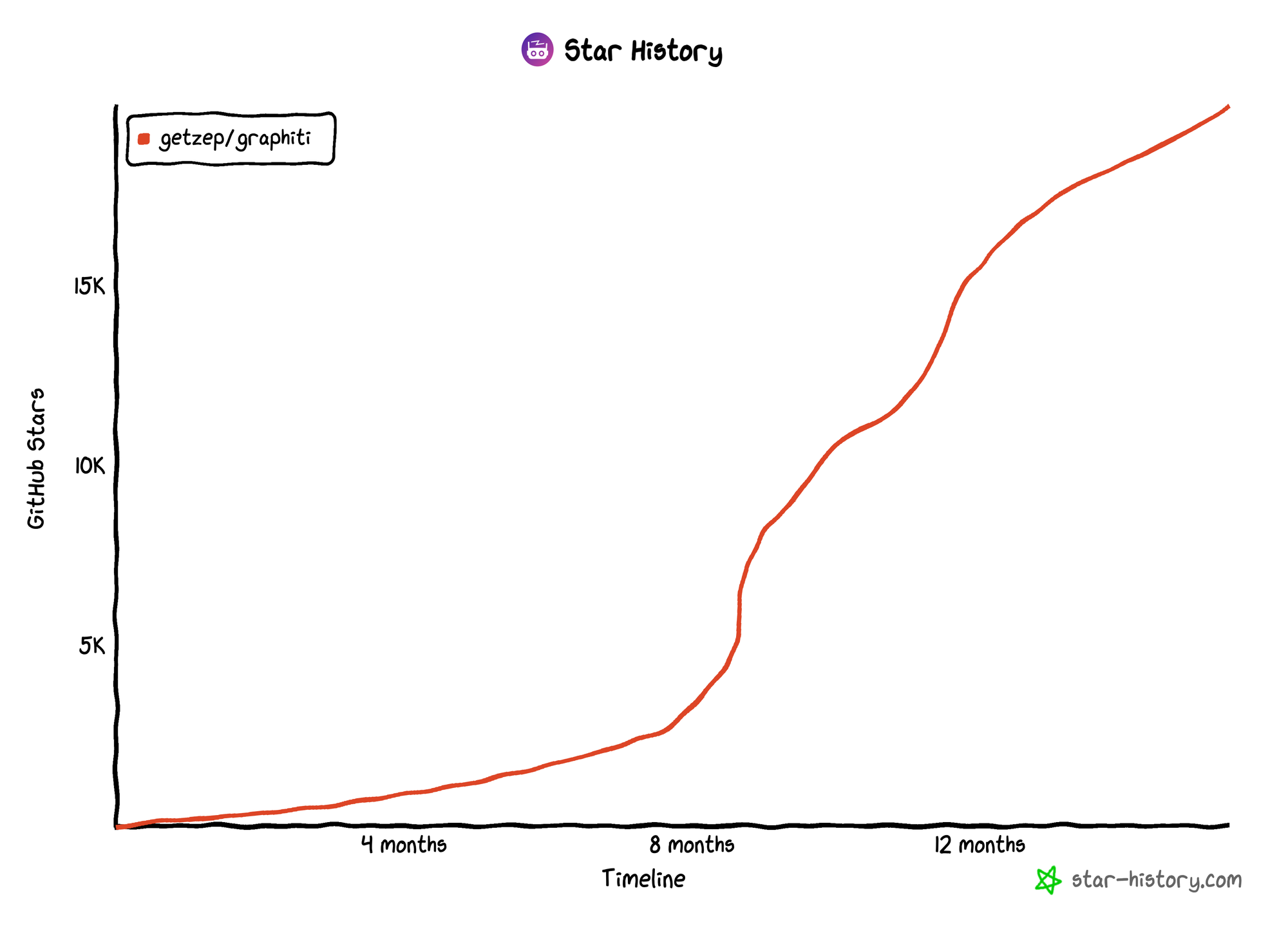
Graphiti Hits 20K Stars! + MCP Server 1.0


Graphiti crossed 20,000 GitHub stars today! Thanks for building with us.
Graphiti is a temporal knowledge graph that powers memory for AI agents. It's a foundational technology for Zep's context engineering platform. Over the past few months we've seen rapid adoption across startups and enterprises, with steady flow of issues, PRs, and production feedback. The MCP server now has hundreds of thousands of weekly users.
Special thanks to the many individual contributors and teams at AWS, Microsoft, FalkorDB, Neo4j, and many other companies for code, reviews, drivers, and advocacy.

MCP Server 1.0
Alongside hitting 20,000 stars, we've also released version 1.0 of the the Graphiti MCP server. Graphiti MCP exposes knowledge graph capabilities through Model Context Protocol standard. It lets Claude Desktop, Cursor, and any other MCP client and MCP-capable agent to directly read from and write to your knowledge graphs. You can build cross-client and local persistent memory into their AI workflows without writing integration code.
Version 1.0 brings multi-provider support and production-ready deployment options.
Big update for Claude Desktop and Cursor users!
— Avi Chawla (@_avichawla) November 5, 2025
Now you can connect all AI apps via a common memory layer in a minute.
I used the Graphiti MCP server that runs 100% locally to cross-operate across AI apps like Claude Desktop and Cursor without losing context.
(setup below) pic.twitter.com/AZrxcS2cR5
Multi-LLM provider flexibility. We've made it easier to witch LLM providers:
- LLM providers: OpenAI (including GPT-5), Anthropic (Claude 4.5), Google (Gemini 2.5), Groq, Azure OpenAI
- Embedding providers: OpenAI, Voyage AI, Google Gemini, Anthropic, local models
Simplified deployment. YAML configuration replaces environment variables as source of truth. Health check endpoints work with Docker and load balancers out of the box. We now have a single cotainer setup that bundles FalkorDB in a single container. Neo4j users can continue to use the separate docker-compose file.
Modern MCP transport. Streaming HTTP replaces deprecated SSE, while STDIO is still available for desktop use.
New Ontology; Better extraction quality. We've added nine preconfigured entity types—Preference, Requirement, Procedure, Location, Event, Organization, Document, Topic, Object—optimized for real-world extraction accuracy. These types emerged from production feedback across thousands of deployments.
Comprehensive testing. 4,000+ lines of test coverage across all providers, async operations, and multi-database scenarios. We test the combinations people actually deploy.
Breaking changes you need to know. Config migrated from env vars to YAML. FalkorDB is now default database (Neo4j still fully supported). Claude Desktop users need to update config paths. Full migration guide in docs.
With Scale, Significant Graphiti Enhancements
The Zep service has seen significant growth recently: How We Scaled Zep 30x in 2 Weeks (and Made It Faster). To address these challenges, we invested heavily in enhancing the performance, reliability, and efficiency of Graphiti. Below are a number of
Deterministic Extraction and Deduplication
The problem: LLM-only extraction created variance, retry loops, and token burn in high-throughput graph implementations. Every entity and edge resolution and deduplication required a model call. This got expensive fast.
We significantly improved efficiency and reliability by adding deterministic, classical-Information Retrieval front-ends and only fall back to LLMs when necessary.
For example, this is how Graphiti now approaches entity deduplication, a previously expensive task:

Entropy-gated fuzzy matching. We compute approximate Shannon entropy over characters in normalized entity names. Low-entropy strings (short, repetitive) are unstable for fuzzy matching. Consider an entity name composed of just a 4-letter first name. These skip heuristics entirely and go straight to the LLM path.
However, high-entropy names can benefit from a more deterministic, heuristic approach to deduplication:
MinHash + LSH candidate generation. We build 3-gram shingles, compute MinHash signatures across multiple permutations, and bucket by fixed-size bands (locality-sensitive hashing). This yields a compact candidate set for deterministic scoring—no LLMs needed here. We evaluate Jaccard similarity between shingle sets and accept matches above 0.9 threshold.
Two-pass, heuristics-first dedupe. First pass resolves per-episode against the live graph. Second pass re-runs deterministic similarity across the union of results to catch intra-batch duplicates. Both passes use the exact/MinHash/LSH/Jaccard path before involving an LLM.
Exact-match fast path. We aggressively short-circuit on normalized exact matches (lowercase + whitespace collapse) before any fuzzy work. Empty or falsey inputs get filtered early to avoid noisy candidates. Hot path stays deterministic and cheap.
Caching for stability. Shingle sets are memoized with an LRU cache. Repeated comparisons within a batch become O(1) after first computation. This matters when LSH buckets contain many near-neighbors.
IR-backed edge workflows. For edges, we pair classical text overlap with embedding similarity to gather candidates, then use hybrid search (RRF) when reconciling related or contradictory edges. This minimizes blind LLM work and constrains prompts to relevant context only.
Outcome: LLMs are amazing, but there's still enormous value in 75-year-old Information Theory techniques! Fewer LLM calls, lower token usage, tighter variance, faster dedupe. Graph quality improved due to fewer retries and cleaner candidate sets.
FalkorDB, AWS Neptune Support; Driver Abstractions
Alongside broader support for LLM providers, Graphiti now supports several more database technologies. The AWS team contributed Neptune and OpenSearch support, while FalkorDB contributed support for their database server. FalkorDB offers multi-tenant GraphID isolation, and is extremely fast at scale.
The Neo4j team assisted with query optimization and guidance on deploying Graphiti at scale.
To support future database backends and improve maintainability, we've implemented database-agnostic interfaces.
OpenTelemetry, Types, Batch Ingestion, and Optimizations
We've added OpenTelemetry to Graphiti cover all graph operations. It's now far easier to debug and monitor production deployments.
Prompt optimizations: we removed JSON indentation and capped some summary artifact size. UTC normalization and updated Cypher patterns mitigate cross-environment brittleness. Result: lower token usage, more stable outputs.
Edges support custom types and Batch Ingestion enables loading many episodes at once.
Summing it Up
Thanks again to contributors and partners—AWS, Microsoft, FalkorDB, Neo4j, and many others.
We'd love your feedback. Try the new features, open issues, submit PRs. See you in the repo.
Find Graphiti on GitHub here: https://github.com/getzep/graphiti