Scaling LLM Data Extraction: Challenges, Design decisions, and Solutions
How we made building Knowledge Graphs faster and more dynamic


Graphiti is a Python library for building and querying dynamic, temporally aware knowledge graphs. It can be used to model complex, evolving datasets and ensure AI agents have access to the data they need to accomplish non-trivial tasks. I'm admittedly biased as one of its creators, but I believe it's a powerful tool that can serve as the database and retrieval layer for many sophisticated RAG projects.
Graphiti was challenging to build. This article discusses our design decisions, prompt engineering evolution, and approaches to scaling LLM-based information extraction. This blog post kicks off a series exploring our challenges while building Graphiti. Reading this will deepen your understanding of both the Graphiti library and provide valuable insights for future development.
Graphiti is open-source; you can find an overview of the project in our GitHub repo.
Architecting the Schema
The idea for Graphiti arose from limitations we encountered using simple fact triples in Zep, our long-term memory service for LLM apps. We realized we needed a knowledge graph to handle facts and other information in a more sophisticated and structured way. This approach would allow us to maintain a more comprehensive context of ingested data and the relationships between extracted entities. However, we still had to make many decisions about the graph's structure and how to achieve our ambitious goals.
While researching LLM-generated knowledge graphs, two papers caught our attention: the Microsoft GraphRAG local-to-global paper and the AriGraph paper. The AriGraph paper uses an LLM equipped with a knowledge graph to solve TextWorld problems—text-based puzzles involving room navigation, item identification, and item usage. Our key takeaway from AriGraph was the graph's episodic and semantic memory storage.
Episodes held memories of discrete instances and events, while semantic nodes modeled entities and their relationships, similar to Microsoft's GraphRAG and traditional taxonomy-based knowledge graphs. In Graphiti, we adapted this approach, creating two distinct classes of objects: episodic nodes and edges and entity nodes and edges.
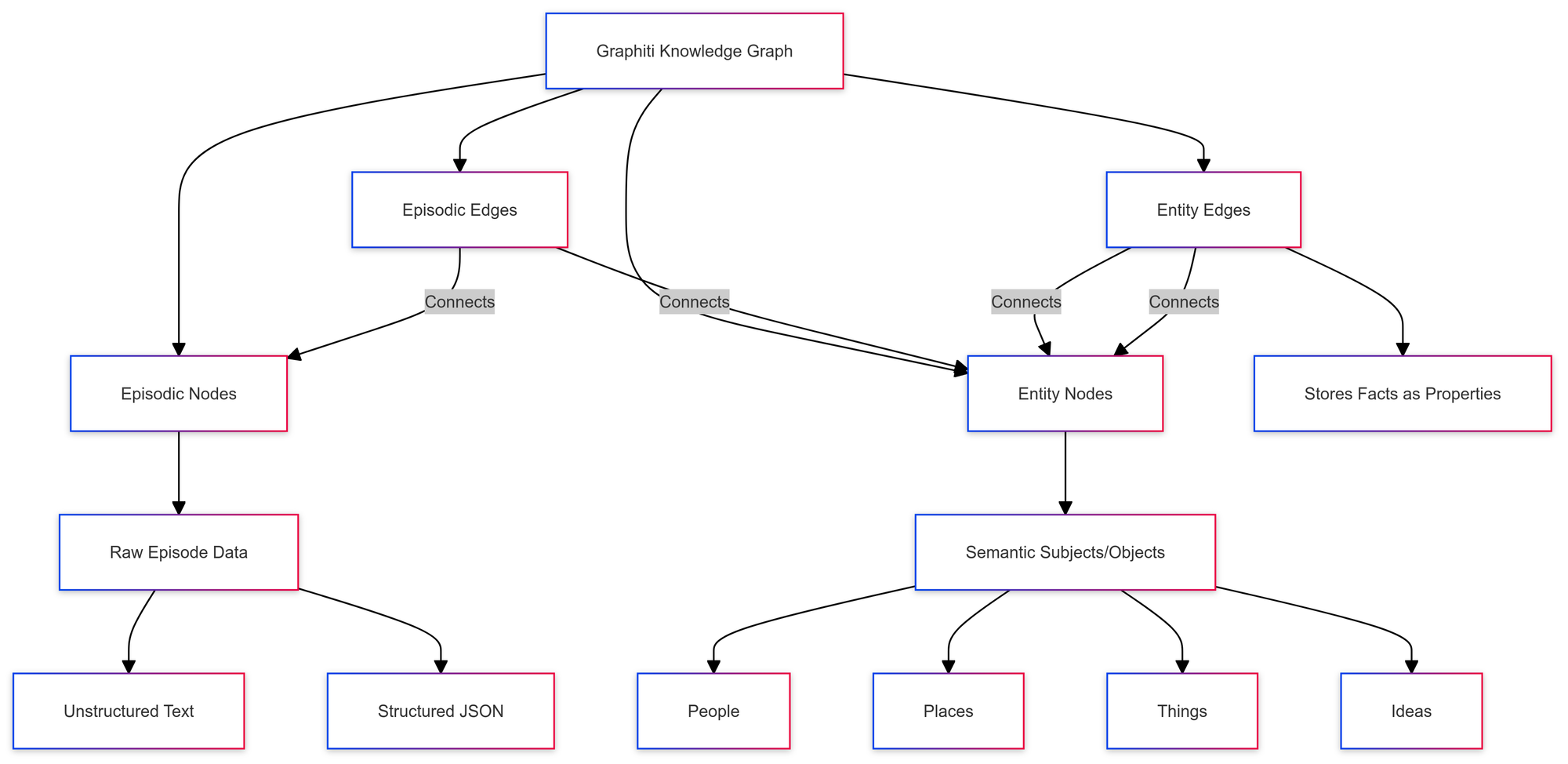
In Graphiti, episodic nodes contain the raw data of an episode. An episode is a single text-based event added to the graph—it can be unstructured text like a message or document paragraph, or structured JSON. The episodic node holds the content from this episode, preserving the full context.
Entity nodes, on the other hand, represent the semantic subjects and objects extracted from the episode. They represent people, places, things, and ideas, corresponding one-to-one with their real-world counterparts. Episodic edges represent relationships between episodic nodes and entity nodes: if an entity is mentioned in a particular episode, those two nodes will have a corresponding episodic edge. Finally, an entity edge represents a relationship between two entity nodes, storing a corresponding fact as a property.
Here's an example: Let's say we add the episode "Preston: My favorite band is Pink Floyd" to the graph. We'd extract "Preston" and "Pink Floyd" as entity nodes, with HAS_FAVORITE_BAND as an entity edge between them. The raw episode would be stored as the content of an episodic node, with episodic edges connecting it to the two entity nodes. The HAS_FAVORITE_BAND edge would also store the extracted fact "Preston's favorite band is Pink Floyd" as a property. Additionally, the entity nodes store summaries of all their attached edges, providing pre-calculated entity summaries.

This knowledge graph schema offers a flexible way to store arbitrary data while maintaining as much context as possible. However, extracting all this data isn't as straightforward as it might seem. Using LLMs to extract this information reliably and efficiently is a significant challenge.
The Mega-Prompt
Early in development, we used a lengthy prompt to extract entity nodes and edges from an episode. This prompt included additional context from previous episodes and the existing graph database. (Note: System prompts aren't included in these examples.) The previous episodes helped determine entity names (e.g., resolving pronouns), while the existing graph schema prevented duplication of entities or relationships.
To summarize, this initial prompt:
- Provided the existing graph as input
- Included the current and last 3 episodes for context
- Supplied timestamps as reference
- Asked the LLM to provide new nodes and edges in JSON format
- Offered 35 guidelines on setting fields and avoiding duplicate information
Given the following graph summary, previous episodes, and new episode, extract new semantic nodes and edges that need to be added:
Current Graph Summary:
{graph_summary}
Previous Episodes Context (Last 3 episodes):
{context}
New Episode:
Text: {episode.text}
Reference Timestamp: {reference_time}
IMPORTANT: The reference timestamp provided above is the point in time from which all relative time expressions in the text should be interpreted. For example, if the text mentions "two years ago" and the reference timestamp is 2022-08-07, it means the event occurred in 2020-08-07.
IMPORTANT: When extracting new nodes and relationships, make sure to connect them to the existing graph structure whenever possible. Look for relationships between new elements and existing nodes. If a new node seems isolated, try to find a meaningful connection to at least one existing node.
Please provide your response in the following JSON format:
{
"new_nodes": [
{
"name": "NodeName",
"type": "SemanticNode",
"properties": {
"name": "NodeName",
"region_summary": "Summary"
}
}
],
"new_edges": [
{
"from": "SourceNodeName",
"to": "TargetNodeName",
"type": "RELATIONSHIP_TYPE",
"properties": {
"id": "UniqueID",
"episodes": ["CurrentEpisodeName"],
"fact": "Fact description",
"valid_from": "YYYY-MM-DDTHH:MM:SSZ or null if not explicitly mentioned",
"valid_to": "YYYY-MM-DDTHH:MM:SSZ or null if ongoing (meaning it is still truthy) or not explicitly mentioned"
}
}
]
}
Guidelines:
1. Use the previous episodes as context to better understand the current episode.
2. Extract new nodes and edges based on the content of the current episode, while considering context from previous episodes.
3. Identify and extract ALL key entities, concepts, or actors mentioned in the current episode, even if they seem implicit.
4. Ensure that any entity performing actions or being central to the current episode is represented as a node.
5. Create nodes for all important entities in the current episode, regardless of whether they already exist in the graph summary.
6. Focus on capturing the complete context of the current episode, including the subject of any actions or statements.
7. Create meaningful relationships between all relevant entities based on the current episode content.
8. Use descriptive and unique names for nodes that clearly represent the entity's role or nature.
9. Choose appropriate relationship types that accurately describe the interaction between nodes.
10. Ensure all required fields are filled for both nodes and edges.
11. For the "valid_from" field in edges, ONLY set a timestamp if a specific start time is explicitly mentioned in the text. If no start time is mentioned, use null. Do not infer or assume a start time.
12. For the "valid_to" field in edges, ONLY set a timestamp if an end time or duration is explicitly mentioned. Use null if the relationship is ongoing or no end time is specified.
13. Pay special attention to temporal expressions that indicate both the start and end of a relationship, such as "was married for 4 years and divorced 1 year ago".
14. Do not include transaction_from or transaction_to in your response. These will be handled separately.
15. Aim for clarity and completeness in your extractions while providing all necessary information.
16. If an actor (such as a user or system) is implied but not explicitly mentioned in the current episode, create a node for them as well.
17. Only create SemanticNode types. Do not create EpisodicNode types.
18. Prefer creating edges over nodes for representing actions, decisions, preferences, or any relational information.
19. When considering whether to create a node or an edge, ask yourself: "Can this concept exist independently, or is it primarily describing a relationship between other entities?" If it's the latter, create an edge instead of a node.
20. Capture implicit relationships by connecting specific instances to their general categories. For example, if a specific brand is mentioned, create a relationship between that brand and the general "Brand" concept.
21. Ensure important details about entities are captured either as properties of the relevant node or as separate nodes connected by appropriate edges.
22. Consider the context from previous episodes, but prioritize new or updated information from the current episode.
23. Pay special attention to hierarchical relationships. If an entity is a type or instance of a more general concept, make sure to create an edge representing this relationship.
24. When new entities are introduced, consider how they relate to existing entities and concepts in the graph. Create edges to represent these relationships.
25. IMPORTANT: Do not infer or assume any temporal information that is not explicitly stated in the text. If a start or end time is not mentioned, always use null for valid_from or valid_to respectively.
26. Ensure that new nodes are connected to at least one existing node whenever possible.
27. Look for implicit relationships between new and existing nodes based on context.
28. If a new node seems isolated, consider its relevance to the overall conversation and find a meaningful way to connect it to the existing structure.
29. If a new node truly represents a new concept with no clear connection to existing nodes, explain why it's important to add it as an isolated node.
30. Prefer creating direct relationships between entities over introducing intermediate nodes.
31. Keep the graph structure as simple as possible while accurately representing the information.
32. Avoid creating nodes for concepts that can be fully represented by relationships between existing entities.
33. When deciding between creating a node or an edge, choose the option that results in the most straightforward graph structure.
34. For events or status changes, focus on updating or creating relationships between involved entities rather than introducing new nodes.
35. Ensure each node represents a distinct entity or concept, not a relationship state or event.
IMPORTANT: Strive for a clean and efficient graph structure. Represent relationships and states through edges whenever possible, minimizing unnecessary nodes.
IMPORTANT: Do not recreate or duplicate existing relationships. Only add new information or update existing relationships when necessary.
Remember to capture all relevant information from the current episode while maintaining and strengthening connections to previously established concepts and entities.This prompt was initially created as a prototype, so we never expected it to make it into a released version of Graphiti. However, there are already many positive aspects to this prompt. Most importantly, it worked well enough to demonstrate that we were onto something with Graphiti and that our vision was achievable.
Additionally, this prompt clearly outlines the necessary steps and context to transform an episode into corresponding graph elements. The prompt uses clear language and thorough guidelines to minimize ambiguity and confusion in the response. Lastly, it utilizes structured JSON output, allowing us to use the output in our code more reliably without encountering formatting errors.
However, the prompt has two major flaws: 1) it won't scale as the knowledge graph grows larger, and 2) it's long and confusing. The scaling issue arises because any real-world database will be significantly larger than an LLM's context window, necessitating a way to avoid passing the entire graph schema into the prompt. The length and complexity of the prompt result in slower processing and less predictable output due to more frequent hallucinations and confusion. It's also complex enough that smaller and medium-sized LLMs like GPT-4o-mini and Llama-3.1-70b struggle to provide quality results.
Separation of Concerns and Prompt Engineering
In Graphiti, LLMs provide output used to build our database, rather than text output for human consumption. This means consistency and predictability in both structure and content are paramount. Additionally, the separation of concerns we employ in our prompts allows us to run many of them concurrently, significantly reducing the total completion time.
As such, we should seek to reduce prompt complexity in our codebase, just as we aim to reduce the complexity of overly long functions. Our strategies are similar: we identify all tasks we're trying to accomplish and separate as many as possible into their own prompts or functions.
With this in mind, we can break our prompt down into the following tasks:
- Extract entities from the current episode
- Deduplicate entities with existing entities
- Extract facts from the episode
- Deduplicate facts with existing facts (from entity edges)
- Determine the timing of the extracted facts
- Expire any existing facts that have been invalidated

In the current iteration of Graphiti, each of these tasks has its own separate prompt. This separation not only makes our output faster, more accurate, and easier to test, but it also allows us to run many tasks in parallel if they don't directly depend on each other, significantly speeding up the process. I'll now cover how the entity extraction and deduplication prompt strategy evolved over time.
The entity extraction prompt is perhaps the simplest of all our prompts. The main insight from our initial mega-prompt is that we no longer require context from the existing graph: LLMs are already adept at zero-shot entity extraction from arbitrary text. This means we've simplified the prompts further by eliminating unnecessary context beyond what's required to accurately complete the task:
Given the following conversation, extract entity nodes from the CURRENT MESSAGE that are explicitly or implicitly mentioned:
Conversation:
{json.dumps([ep['content'] for ep in context['previous_episodes']], indent=2)}
<CURRENT MESSAGE>
{context["episode_content"]}
Guidelines:
1. ALWAYS extract the speaker/actor as the first node. The speaker is the part before the colon in each line of dialogue.
2. Extract other significant entities, concepts, or actors mentioned in the conversation.
3. Provide concise but informative summaries for each extracted node.
4. Avoid creating nodes for relationships or actions.
5. Avoid creating nodes for temporal information like dates, times or years (these will be added to edges later).
6. Be as explicit as possible in your node names, using full names and avoiding abbreviations.
Respond with a JSON object in the following format:
{
"extracted_nodes": [
{
"name": "Unique identifier for the node (use the speaker's name for speaker nodes)",
"labels": [
"Entity",
"Speaker for speaker nodes",
"OptionalAdditionalLabel"
],
"summary": "Brief summary of the node's role or significance"
}
]
}
One can quickly see that this prompt is much simpler and so the output is much more predictable, allowing us to use smaller LLMs and more easily engineer the prompt to the one specific task.
The first iteration of the node deduplication prompt also had its necessary context reduced: now that we had already extracted the entities and their summaries from the episode, the episode no longer provided necessary context to complete our task. In addition, already knowing what the extracted nodes are allows us to solve the graph size scaling problem: we can simply extract the most similar existing nodes to our newly extracted nodes and let the LLM find any duplicates from their. We find these similar nodes through a hybrid search, meaning that we can also cap the maximum context for this promo at a relatively small token size, so this prompt won’t indefinitely scale linearly with graph size. The prompt is as follows.
Given the following context, deduplicate nodes from a list of new nodes given a list of existing nodes:
Existing Nodes:
{json.dumps(context['existing_nodes'], indent=2)}
New Nodes:
{json.dumps(context['extracted_nodes'], indent=2)}
Important:
If a node in the new nodes is describing the same entity as a node in the existing nodes, mark it as a duplicate!!!
Task:
If any node in New Nodes is a duplicate of a node in Existing Nodes, add their uuids to the output list
When finding duplicates nodes, synthesize their summaries into a short new summary that contains the
relevant information of the summaries of the new and existing nodes.
Guidelines:
1. Use both the name and summary of nodes to determine if they are duplicates,
duplicate nodes may have different names
2. In the output, uuid should always be the uuid of the New Node that is a duplicate. duplicate_of should be
the uuid of the Existing Node.
Respond with a JSON object in the following format:
{
"duplicates": [
{
"uuid": "uuid of the new node like 5d643020624c42fa9de13f97b1b3fa39",
"duplicate_of": "uuid of the existing node",
"summary": "Brief summary of the node's role or significance. Takes information from the new and existing nodes"
}
]
}
While this prompt is simpler than our initial prototype, the task and desired output still feel somewhat unintuitive. This creates potential for LLM confusion and inconsistent results that could be incorrect or, more critically, break our code if the LLM doesn't strictly follow all provided guidelines. To simplify this prompt further, I decided to write out what I wanted the LLM to do in pseudocode, then work backwards to build a better prompt. Here's the pseudocode I drafted:
for each node in extracted_nodes:
for each existing_node in existing_nodes:
if node is existing_node:
return (existing_node.uuid, updated_summary)As I examined this pseudocode, I realized the first loop is entirely deterministic. By creating a prompt to handle the remaining task for each node in the extracted nodes list, we could greatly simplify the output. This approach further reduced the prompt's context, as we'd only need to pass in existing nodes similar to the single new node being resolved. Additionally, we could run each deduplication prompt in parallel, speeding up our results. This insight led us to the current node deduplication prompt we use today.
Given the following context, determine whether the New Node represents any of the entities in the list of Existing Nodes.
Existing Nodes:
{json.dumps(context['existing_nodes'], indent=2)}
New Node:
{json.dumps(context['extracted_nodes'], indent=2)}
Task:
1. If the New Node represents the same entity as any node in Existing Nodes, return 'is_duplicate: true' in the
response. Otherwise, return 'is_duplicate: false'
2. If is_duplicate is true, also return the uuid of the existing node in the response
3. If is_duplicate is true, return a summary that synthesizes the information in the New Node summary and the
summary of the Existing Node it is a duplicate of.
Guidelines:
1. Use both the name and summary of nodes to determine if the entities are duplicates,
duplicate nodes may have different names
Respond with a JSON object in the following format:
{
"is_duplicate": true,
"uuid": "uuid of the existing node like 5d643020624c42fa9de13f97b1b3fa39 or null",
"summary": "Brief summary of the node's role or significance. Takes information from the new and existing node"
}
This prompt yields a much simpler output and has performed significantly better for us in practice. The evolution of the edge extraction and deduplication prompts followed a similar path, so I won't delve into them here. However, I encourage interested readers to explore them in our codebase on GitHub. Compared to our initial prompt, our current architecture provides more accurate and testable results much faster.
Conclusion
In this article, we've taken an initial dive into some of the decisions and challenges encountered during Graphiti's development. We explored the importance of a flexible and structured schema when building a knowledge graph, the process and significance of prompt engineering, and how many traditional development strategies—such as separation of concerns—can be applied to prompt engineering. We also highlighted the crucial role of speed and scalability in LLM projects that build databases.
In our next article, we'll discuss one of Graphiti's key differentiating features: its first-class temporal architecture, and the challenges we faced implementing it. I hope you found this discussion enlightening. If this post piques your interest, please check out our GitHub.