How We Scaled Zep 30x in 2 Weeks (and Made It Faster)

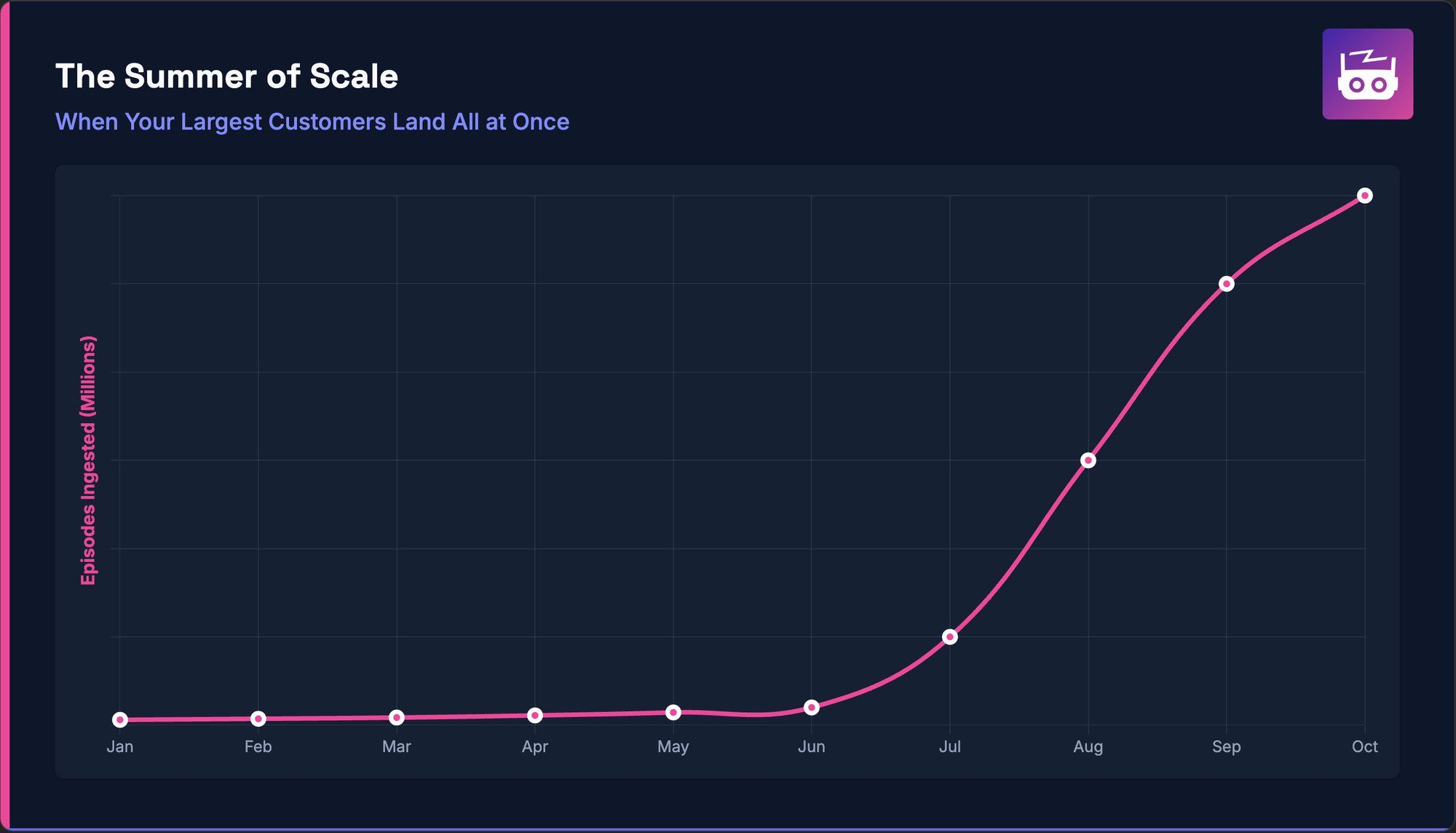
This summer, our largest enterprise customers landed all at once. Service usage increased 30x in two weeks. We went from handling thousands of hourly requests to millions overnight.
Our infrastructure didn't just bend under the load. It broke. Hard. 😬
Context retrieval latency spiked from a P95 of 200ms to over 2 seconds. Episode processing crawled to 60 seconds. LLM costs exploded to 3-5x our provisioned capacity, with rate limit errors cascading to customer-facing failures. Throwing more hardware at our graph database couldn't stop the system from melting down.

Context retrieval sits on the critical path for every agent interaction. When it takes 2 seconds instead of 200ms, end users wait. When it fails, agents hallucinate. We were breaking production for customers with millions of users.
Six weeks later, we not only stabilized Zep but made it significantly faster than before the crisis. Graph search now returns results in 150ms (P95), down from 600ms. Context retrieval, which is a retrieval pipeline with many search components, dropped to 200ms (P95). And episode processing latency improved 92%, from around to 4 seconds. And we cut LLM token usage in half while maintaining accuracy above 80% on the LongMemEval benchmark, up 10% since our early 2025 paper.
Here's how we did it.
Our virtual Staff Engineer. A realtime application built with Zep and Anam AI. 💥
The Challenge: When Growth Exposes Bottlenecks
Over eight weeks this summer, we onboarded our biggest enterprise customers. These weren't gradual rollouts. Customers exceeded their own growth forecasts. Service volume increased 30x in just two weeks.
The rapid scaling revealed bottlenecks we didn't know existed:
Our graph database was doing too much. We'd been using our graph database to handle graph operations, vector search, and BM25 full-text search. We were adding new vectors and texts too fast, all day long. Under 30x load, search latencies spiked dramatically. The system was trying to be a Swiss Army knife when we needed specialized tools.

LLM costs spiraled out of control. We use LLMs for graph construction, entity extraction, relationship inference, and fact deduplication. Burst usage hit 3-5x our provisioned throughput, triggering rate limit errors that cascaded to customer applications. We were dramatically underwater on margins.

Our Python-based LLM gateway choked. We used an LLM Gateway to route calls, program fallbacks, and for granular cost tracking. The proxy ran on 8-12 pods with high memory footprints and at times significant CPU load. The final straw were memory leaks resulting in service outages every few hours. The operational overhead was crushing us.
These weren't isolated issues. Everything broke simultaneously, and our customers' production systems were on the line. We had non-negotiable SLA targets. Missing these meant breaking production for customers with millions of users.
The Solution: A Multi-Pronged Technical Overhaul
We took a systematic approach to rearchitecting under fire. The strategy came down to three principles: separate concerns early, question every LLM call, and build for burst traffic instead of average load.
Specialized search infrastructure. Our graph database was handling graph operations, vector search, and BM25 full-text search all at once. We needed to separate these concerns and use purpose-built tools for each job. We considered OpenSearch but estimated it would cost over $50K per month in infrastructure. Instead, we moved to a high-performance, very high-scale retrieval infrastructure optimized for our use case. We offloaded all vector and BM25 search to this dedicated service, stripped content storage from the graph database, and let our graph database focus solely on what it does best: graph operations. The result: 65ms P75 search latency at massive scale, a fraction of the cost, and far lower operational overhead.

Classical NLP and Information Retrieval techniques over LLM calls. We realized we'd been treating LLMs as the solution to every problem, even when simpler approaches would work better. We replaced expensive LLM calls with Shannon Entropy for information density scoring, TF-IDF for content deduplication, and LSH (Locality-Sensitive Hashing) for fast similarity matching. We compressed context before LLM calls by stripping low-signal content and optimized prompts to reduce token overhead. This cut LLM token usage by 50% while keeping costs within our prepurchased inference capacity.

Purpose-built LLM gateway in Go. We replaced the unstable Python proxy with a tiny, blazing-fast custom Go service. The new system has a minimal memory footprint, handles intelligent rate limiting and queuing, smooths peak usage under our provisioned throughput, and pushes usage data direct into our data lake. We eliminated rate limit errors entirely and brought LLM costs under budget.

These changes weren't just optimizations. We restored 99.95%+ uptime under 30x load, and dramatically reduced and avoided infrastructure costs. We made significant architectural decisions under pressure, with production customers depending on us to get it right.
What We Shipped Along the Way
While rearchitecting the Zep's core infrastructure, we also shipped features that improve how developers work with Zep:
Improved JSON graph building. We enhanced the quality of entity extraction from JSON documents, ensuring more reliable and comprehensive capture of all entities during knowledge graph construction.
Enhanced deduplication reliability. We improved entity and relationship deduplication using traditional NLP and algorithmic approaches. Fewer duplicate nodes, better graph quality.
Relevance scoring. Search results now include a normalized relevance field (0-1 scale) in addition to raw reranker scores. This makes it easier to set thresholds and compare result quality across different queries.
Temporal fact clarity. Context templates now explicitly clarify which facts are currently true versus historical facts. This helps LLMs correctly interpret the temporal validity of information, reducing confusion about what's current and what's past.
Enhanced graph episode display. Graph visualizations now include episodic nodes and edges alongside entity data, with truncation indicators when large graphs exceed display limits. This provides more complete context for memory exploration.
Ontology visualization. You can now view and explore the custom entity and edge types defined in your knowledge graph ontology through an interactive visualization interface. It makes understanding your graph's structure much easier at a glance.

Project Info API endpoint. A new lightweight endpoint retrieves basic project information (UUID, name, description, created_at), allowing programmatic evaluation of Zep projects.
Looking Forward
These improvements laid the foundation for the next phase of growth. We learned to separate concerns early, question every expensive operation, and build for burst traffic instead of average load.
Thank you to our customers for your patience and partnership through the challenges. Your trust made this possible.
We'll share deeper technical dives in future posts. If you're building agents that need reliable context, check out our documentation, explore Graphiti on GitHub, or sign up for Zep.