Stop Using RAG for Agent Memory


Based on my recent talk at the AI Engineer World's Faire, here's why you shouldn't be using RAG for memory—and what to do instead.
The Problem: Agents That Forget
I'm Daniel, founder of Zep AI. We build memory infrastructure for AI agents, and I'm here to tell you: you're doing memory all wrong.
Well, maybe not you directly—but quite possibly the framework you're using to build your agents.
My Hot Takes
Let me be clear about my position:

Hot Take #1: Stop Using RAG as Memory

Hot Take #2: Knowledge Graphs Are the Future of Agent Memory
Why Memory Matters
Before diving into the above, let's establish why this matters:

We're routinely building agents that suffer from three critical problems:
- Lost Context: Agents forget essential information from past interactions
- Generic Responses: Without proper memory, outputs become impersonal and inaccurate
- Eroded Trust: Users lose confidence when agents can't remember basic preferences
This definitely isn't the path to AGI—or more practically, to retaining customers.
The RAG Memory Problem
Let me illustrate why RAG fails as memory with a concrete example:
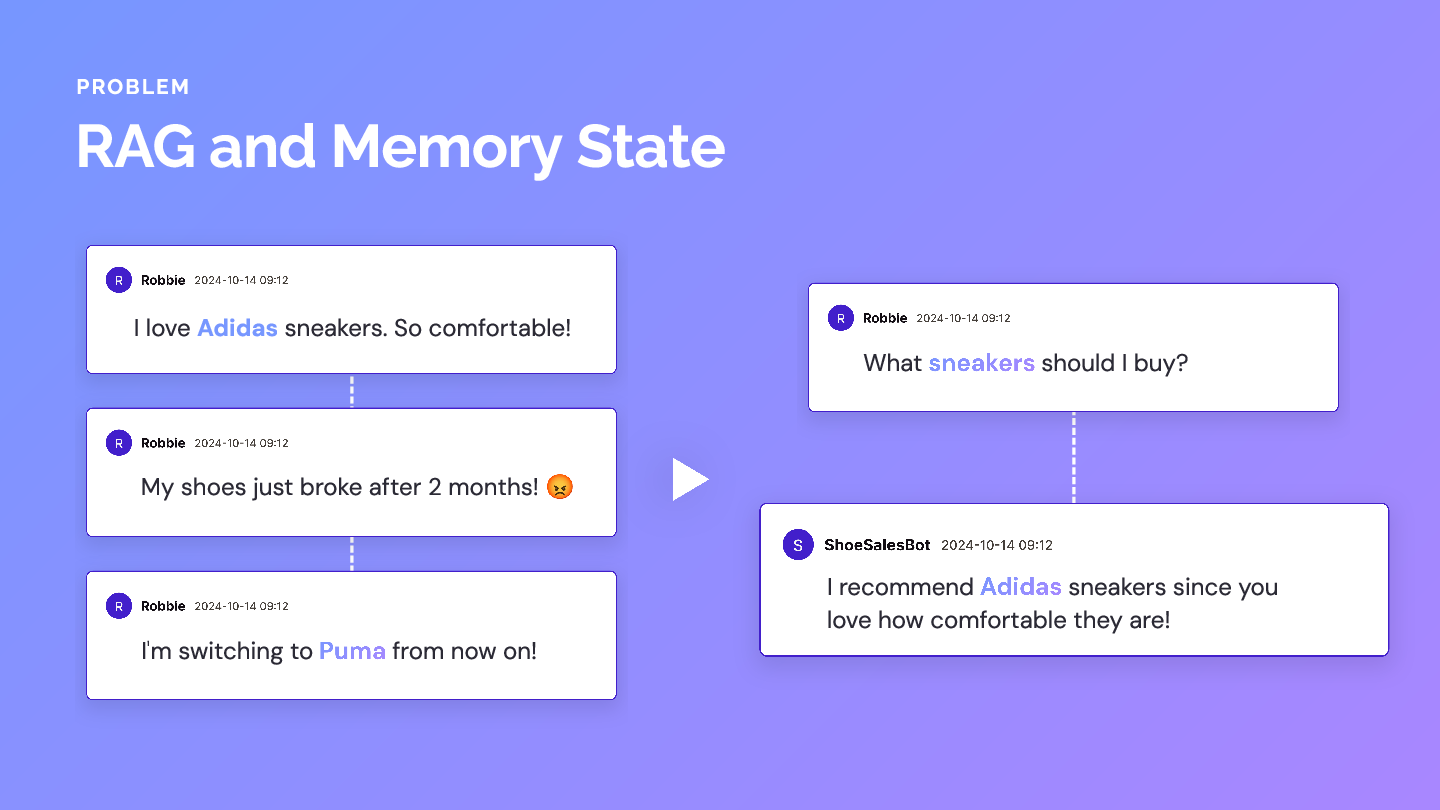
Consider this e-commerce scenario:
- User expresses love for Adidas sneakers
- Their shoes break after 2 months, causing frustration
- User switches preference to Puma
- User asks: "What sneakers should I buy?"
In a RAG-based system, the query "What sneakers should I buy?" is most semantically similar to the original Adidas preference. The vector database returns that outdated fact, and the agent incorrectly recommends Adidas—completely ignoring the preference change.

The fundamental issues are:
- Temporal Sequence: Which fact came first?
- Causal Relationships: Broken shoes → disappointment → preference change
- Fact Invalidation: "Love Adidas" should be overridden by later events
Vector Embeddings vs Knowledge Graphs
Here's the visual representation of the problem:

In vector space, these facts exist as isolated points with no explicit relationships. The query finds the most similar embedding, but completely misses the causal chain and temporal context.
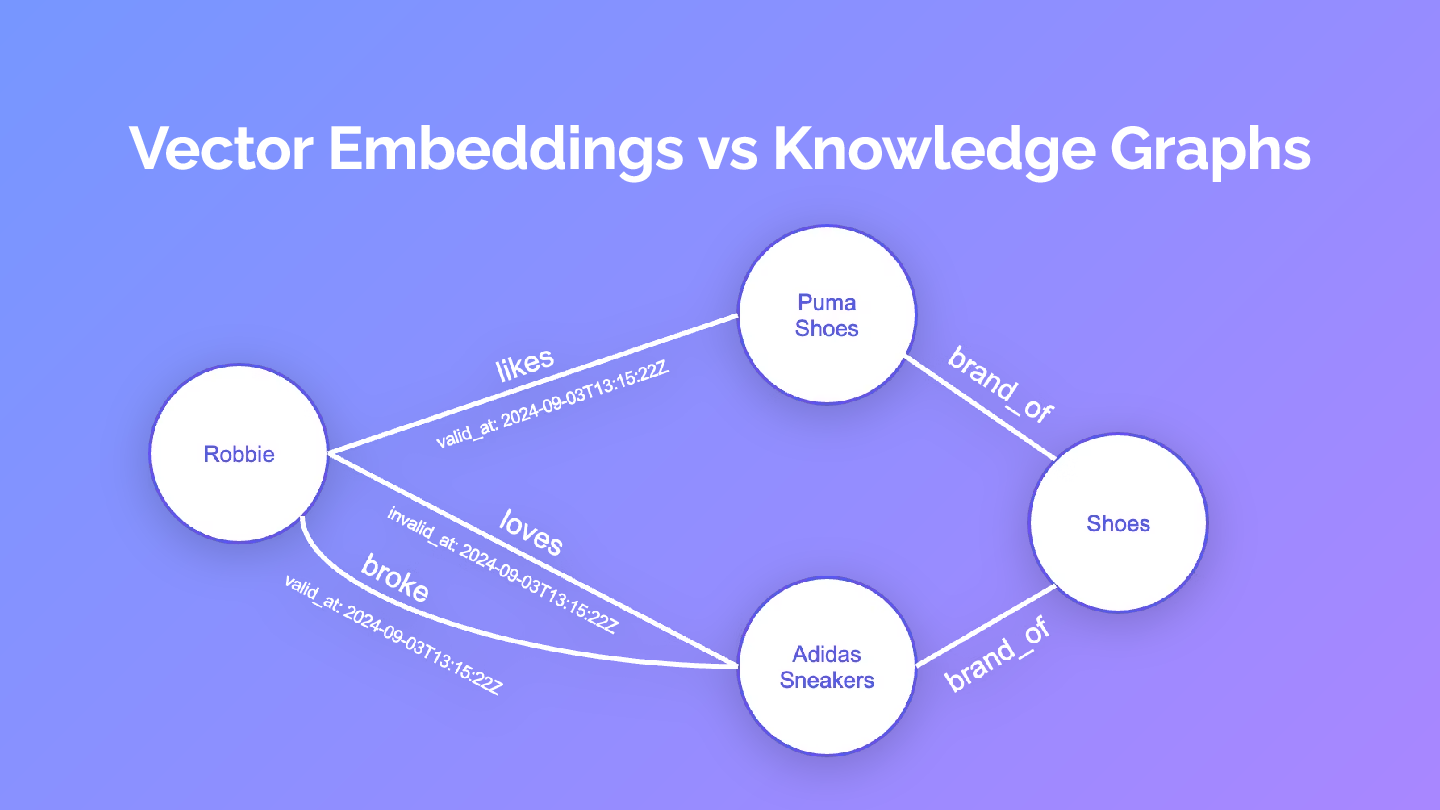
Knowledge graphs, however, can explicitly model these relationships with temporal validity periods. Notice how the graph shows:
- The "loves" relationship is invalidated on a specific date
- The "broke" relationship creates a causal link
- The new "likes" relationship for Puma is currently valid
Introducing Graphiti
This brings us to our solution:
Graphiti is Zep's open-source framework for building real-time, dynamic knowledge graphs. It's designed specifically to address the memory problems I've outlined.
Key features:
- Temporally-Aware: Tracks when events occurred AND when they were learned
- Relational: Entities + relationships + communities
- Real-time: Dynamic updates without expensive recomputation
The Secret Sauce: Bi-Temporal Memory

Here's how Graphiti's temporal model works. Every fact tracks four timestamps:
- created_at: When Graphiti learned the fact
- valid_at: When the event actually occurred
- invalid_at: When the fact became untrue
- expired_at: When Graphiti learned it was no longer valid
This enables powerful temporal reasoning: "What did the user prefer in February?" becomes answerable.
Smart Conflict Resolution
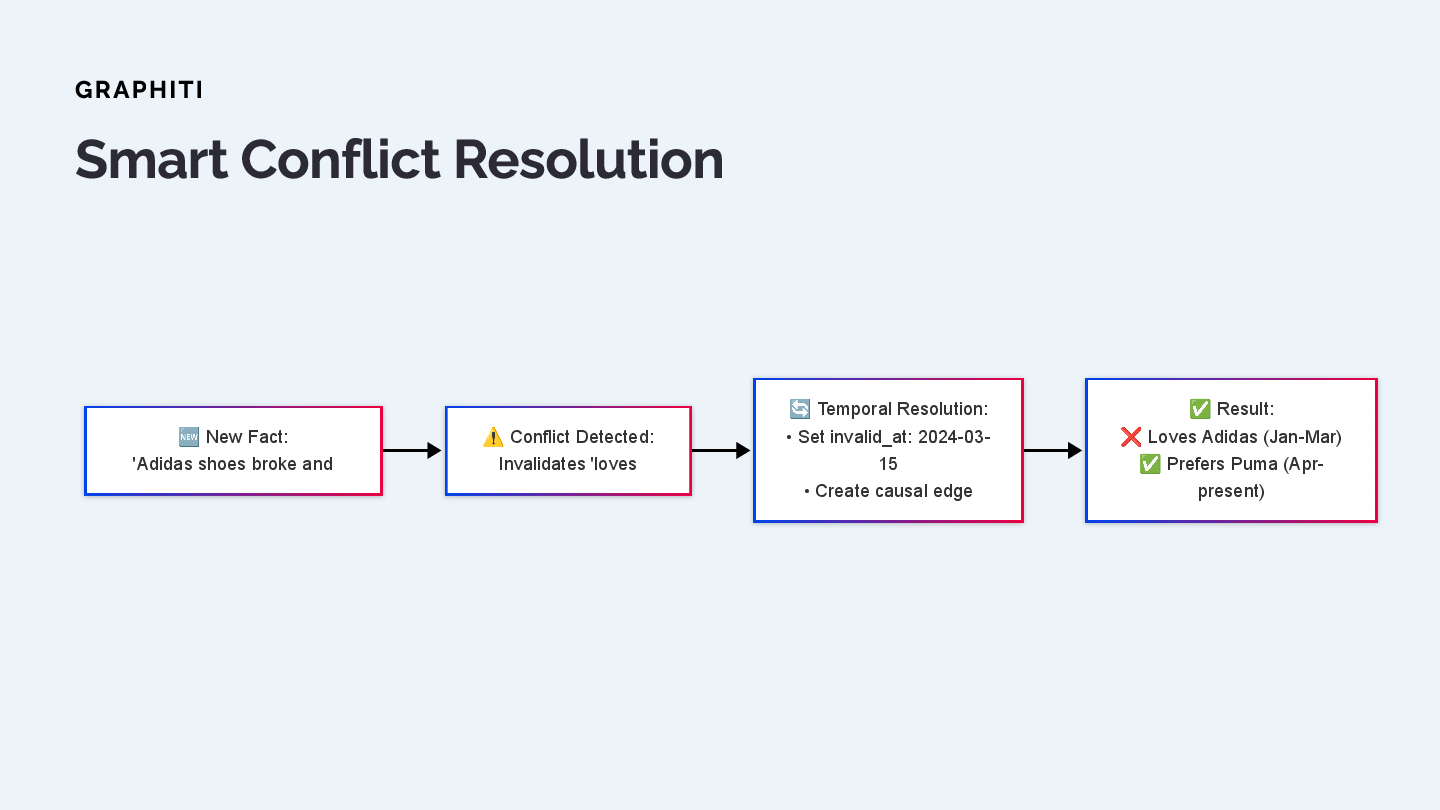
When Graphiti encounters conflicting information, it doesn't just add another embedding. Instead:
- New Fact: "Adidas shoes broke and [user unhappy]"
- Conflict Detected: This invalidates the "loves Adidas" relationship
- Temporal Resolution: Set invalid_at date and create causal edge
- Result: Clear temporal boundaries for each preference
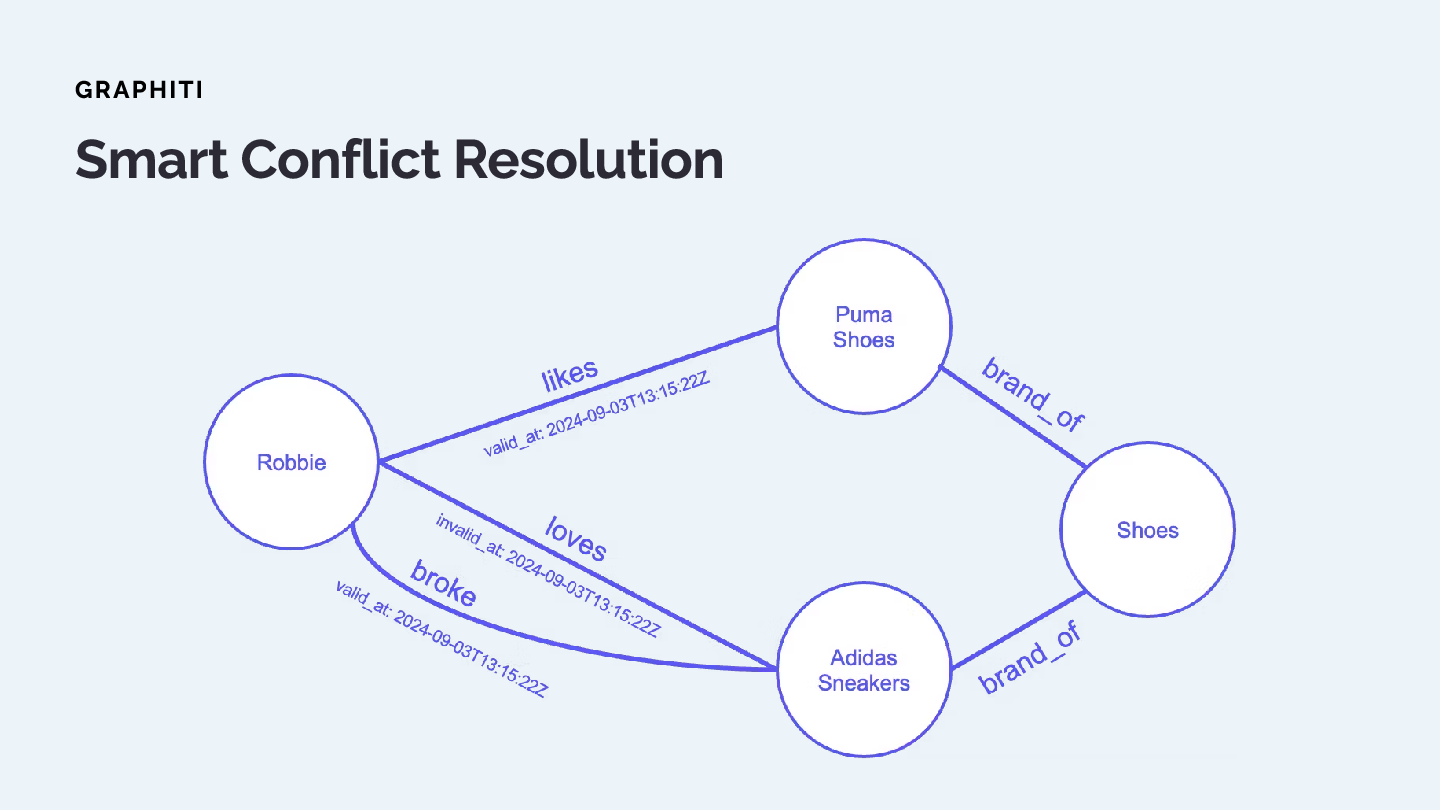
The resulting graph preserves history while clearly indicating current validity. This is "a closer approximation to how humans might process and recall changing state over time."
Don't Throw Away the Embeddings!
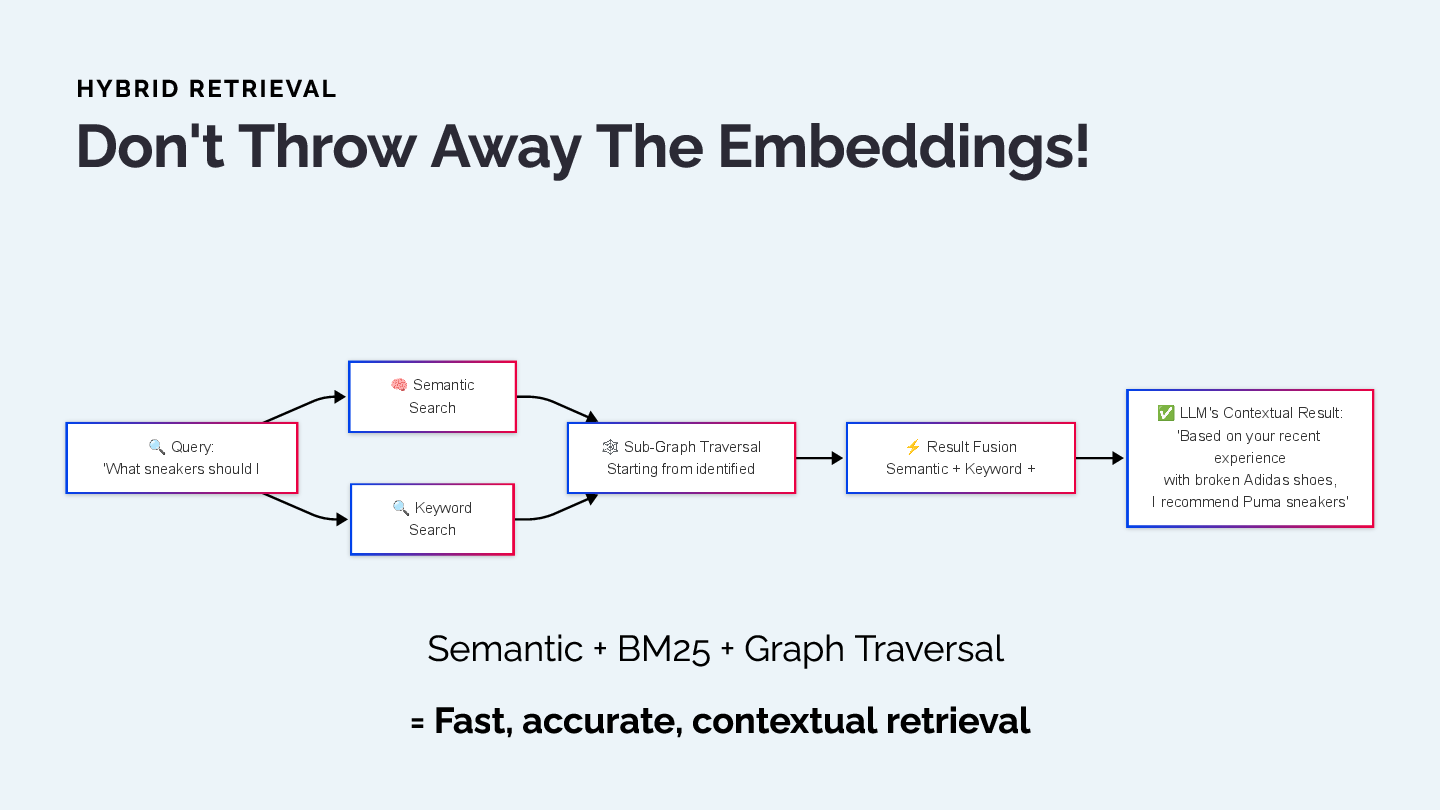
Graphiti doesn't abandon embeddings—it makes them smarter. The system uses a hybrid approach:
- Semantic Search: Find relevant content via embeddings
- Keyword Search: BM25 full-text search for specific terms
- Sub-Graph Traversal: Navigate relationships from initial results
- Result Fusion: Combine all approaches for comprehensive context
The result: Fast, accurate, contextual retrieval that operates in milliseconds, not seconds.
Domain-Specific Memory

One of Graphiti's powerful features is domain modeling. A mental health application needs to store very different types of memories than an e-commerce agent.
Graphiti allows you to define custom entities and edges using familiar tools like pydantic, giving you:
- Any Data Source: Integrates conversational and business data dynamically
- Relevant Retrieval: Only entities and facts relevant to your application are retrieved
- Familiar Tools: Use pydantic to define your entity and edge ontology
The Right Tool for the Job

I'm not advocating replacing RAG everywhere. Each approach has its strengths:
| Approach | Use Case | Updates | Temporal Handling | Query Speed |
|---|---|---|---|---|
| Semantic RAG | Static Documents | Batch recomputation | Coexist unresolved | Fast (ms) |
| Microsoft GraphRAG | Static Corpus Summarization | Batch recomputation | Limited to LLM judgement | Slow (seconds) |
| Graphiti | Real-time, Dynamic Data | Real-time incremental | Edge invalidation with temporal tracking | Fast (ms) |
Most agent applications could benefit from using both a RAG approach for static knowledge AND Graphiti for dynamic memory.
The Bottom Line

Agent memory is not about knowledge retrieval.
Proven Results

The proof is in the performance. Zep/Graphiti crushes benchmarks designed to replicate complex real-world enterprise scenarios:
- Zep: 71.2% accuracy
- Full-context baseline: 60.2% accuracy
We published a comprehensive paper detailing the architecture and performance results. You can find it at the arXiv link in the slide.
Beyond Simple Memory
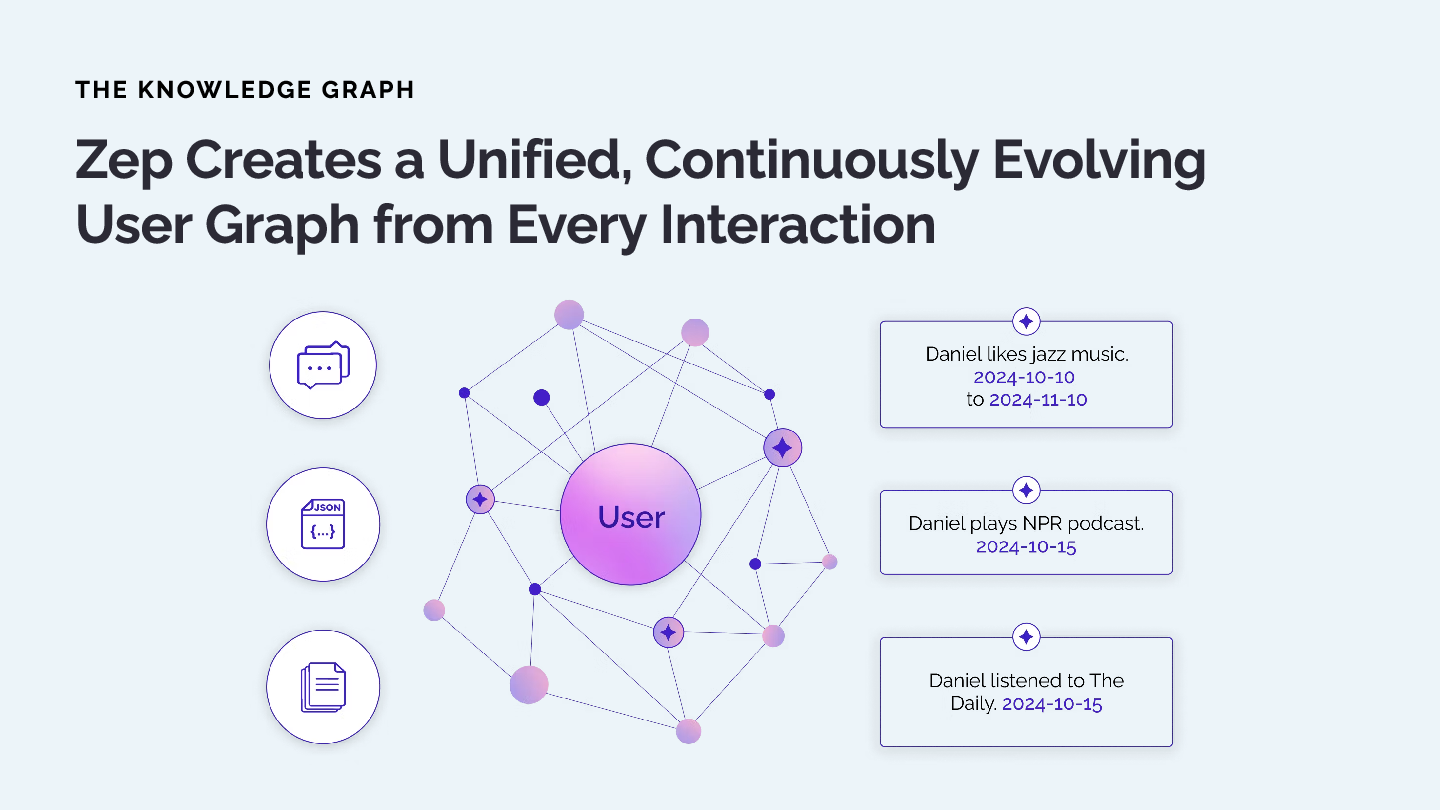
Zep is built on Graphiti, and goes beyond simple agent memory to build a unified customer record. It creates a continuously evolving user graph that integrates:
- Chat conversations
- Business data from SaaS applications
- Line-of-business systems (CRM, billing, etc.)
This gives your agents a comprehensive, real-time understanding of each user, enabling them to solve complex problems effectively.
Get Started
The future of agent memory is here, and it's built on temporally-aware knowledge graphs.

Ready to try it? git.new/graphiti
The Graphiti framework is open source and ready to use today. Looking for a cross-platform MCP Memory Service? Try our Graphiti MCP.
This blog post is based on my recent talk about agent memory and knowledge graphs at AI Engineer World's Faire 2025. You can watch the full recording on YouTube.