A Survey of Embedding Models (and why you should look beyond OpenAI)
User experience can be severely impacted when AI chat apps and agents are slow to respond. Embedding model performance can contribute to this problem. Is OpenAI's embedding API always the best fit?


Just looking for the embedding model latency results? Skip the intro.
When we talk about machine learning model performance, we’re most often referring to how well a model performs at a specific task. For data scientists and machine learning engineers, these may include measures such as accuracy and loss. As text-based generative AI applications such as Chatbots and agents become an everyday part of our lives, we’re going to need to consider another performance dimension that significantly impacts user experience: model latency. That is, the time it takes the model to generate a result. The slower this process, the poorer the chat user experience.
OpenAI’s GPT-3.5-Turbo model has significantly reduced the time to first byte of streaming responses. However, building the prompts that get sent to LLMs is often a lengthy and slow process, potentially with multiple calls to other models, and 3rd-party or internal services to generate the in-context learning content that is used by the LLM to generate a response.
While documents are usually embedded before prompt creation, search term embeddings must be created on the fly when the search is executed. This puts the speed of embedding on the critical path to generating an LLM result.
Why vector databases and embedding models are a key AI technology
One of the most common prompt generation tasks is the retrieval of relevant information from a collection of documents using a vector database. Vector databases store a mathematical representation of a document called an embedding and use techniques such as Approximate Nearest Neighbors to compare documents to each other, or to a search term. In machine learning, this task is called Semantic Search.
Embeddings are generated by specialized language models designed to perform well for this task. There are many different embedding models, each with unique performance characteristics: accuracy, speed, storage and memory usage, and more. They may also be multi-lingual, or trained for a specific natural language. Some are even trained for specific business or scientific domains.
While the documents are usually embedded before prompt creation, the search term embeddings must be created on the fly when the search is executed. This puts the speed of embedding on the critical path to generating an LLM result.
A semi-scientific survey of embedding model latency
As we discussed above, slow prompt creation impacts the user experience and a key task in generating prompts is searching for relevant content using semantic search. While the cost, memory usage, and ease of implementation of an embedding model should all be considered, this survey focuses solely on the speed of embedding, and where available, MTEB benchmark performance on semantic similarity search tasks.
We tested two Embedding API services and several open-source embedding models supported by the sentence-transformers package. The open-source models we selected are representative of model families that score high on the MTEB benchmarks and perform well on CPUs. There are many other models and you should experiment for your use case, using benchmarks as guidance, not gospel.
| Model | Deployment Type | MTEB Retrieval Score |
|---|---|---|
| OpenAI text-embedding-ada-002 | API Service | 49.25 |
| Google Vertex AI textembedding-gecko@001 | API Service | Unknown - introduced May 2023 |
| sentence-transformers/gtr-t5-xl | Local CPU execution | 47.96 |
| sentence-transformers/all-MiniLM-L12-v2 | Local CPU execution | 42.69 |
| sentence-transformers/all-MiniLM-L6-v2 | Local CPU execution | 41.95 |
The API tests were run from both GCP and AWS, which is representative of many applications today. The local models were tested on several cloud instances and my MacBook Pro M1 with 16GB of RAM. See details below.
The results
tl;dr OpenAI's embedding API was significantly slower than Google's new embedding API. Open-source models running on a CPU were the fastest. There aren't yet retrieval benchmarks for Google's new embedding model, and the open source model's score lower on the MTEB than OpenAI's. Despite this, both Google's offering and the open-source models are worth evaluating if OpenAI's latency concerns you.
OpenAI's text-embedding-ada-002 model is a go-to for many developers. Apps often use an OpenAI LLM, and it makes sense that developers would use the same API to embed documents. OpenAI has also recently significantly reduced the price of using this API.
It turns out, as measured from both AWS and GCP, the OpenAI embedding API's latency is significantly higher—by an order of magnitude—than Google's new textembedding-gecko@001 model (as measured from GCP alone).
OpenAI variance is also very high—something many have experienced with OpenAI's APIs as they've, at times, struggled to scale. It's possible that model latency is far lower when using the Azure OpenAI Service for apps running in Microsoft Azure.
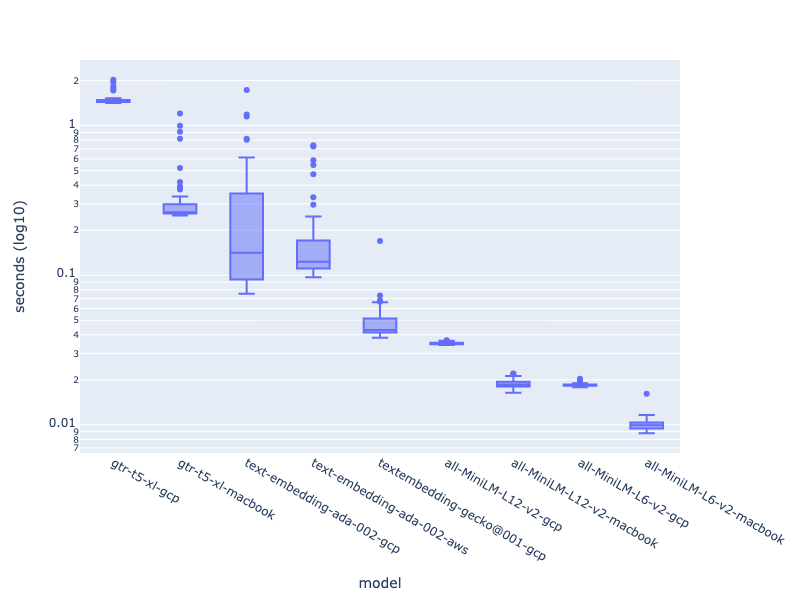
Unsurprisingly, the open-source embedding models running on a local CPU outperformed both Google and OpenAI's API services. Transiting networks is slow. What was surprising is how well Google's model performed relative to the local open source models. I only measured from GCP and so the API certainly had home-court advantage.
Latency is often measured at the 95th percentile, termed p95 by DevOps and SRE-types. Below are the p95 model results (not on a log scale). OpenAI API p95 responses took almost a minute from GCP and almost 600 ms from AWS.
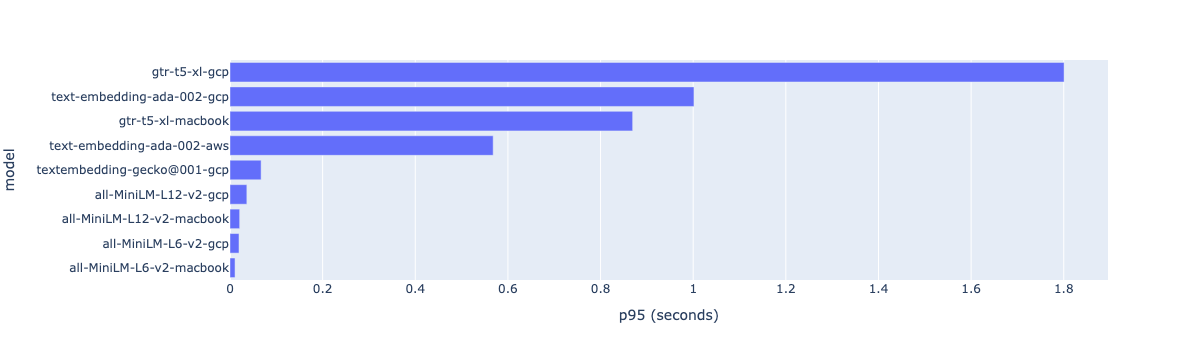
The gtr-t5-xl model, the open-source model in this survey with the closest MTEB score to OpenAI's offering, performed poorly versus all other models. It's likely that with a GPU performance would increase significantly for large batch embedding (see below).
The all-MiniLM family of open source models are very fast (and being smaller models are quite memory efficient). Given their speed and relative ease of deployment (see this Langchain example), it's worth evaluating how well they perform for your specific use case.
Your Mileage May Vary with embedding model performance
The sentence-transformers team have created a large number of different models, and for good reason. Each model has a different combination of performance characteristics and is intended for different uses. Spoken language, sentence length, vector width, vocabulary, and other factors all impact how a model performs. Some models may perform better for a domain than others. It's worth using the MTEB and other benchmarks as guidance when selecting a model, but always experiment with your own data.
Why bother using CPUs for sentence embeddings?
When testing the open-source models, we focussed on CPU performance, rather than GPU. CPU deployment is cheap and easy to scale. While embedding models, like many deep learning models, perform best on GPUs when running inference over large datasets, our primary interest here is how the models perform for a single short sentence. GPU usage in this scenario can often be slower than CPUs, as transferring data to the GPU is more expensive than moving the same data from memory to the CPU.
Using SentenceTransformer Models with Langchain
Using SentenceTransformer embedding models with Langchain is relatively simple and easy to implement, even if you're not using a GPU. Langchain ships with a HuggingFace integration, allowing any embedding models hosted on HuggingFace to be used as a Langchain Embedding.
Note: You'll need to ensure you have sentence_transformers installed.
from langchain.embeddings import HuggingFaceEmbeddings, SentenceTransformerEmbeddings
# Using the lightest-weight model we evaluated above
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
text = "Iceland is wonderful to visit"
embedded_docs = embeddings.embed_documents([text])Read the Langchain Indexes and VectorStores documentation on how to use the above in your chain or agent code.
The test methodology
We sampled embedding speed over 50 iterations for each of the models. The text that was embedded was relatively short and intended to be representative of the types of searches that are run by LLM-based applications against vector databases when composing a prompt.
texts = ["Visa requirements depend on your nationality. Citizens of the Schengen Area, the US, Canada, and several other countries can visit Iceland for up to 90 days without a visa."]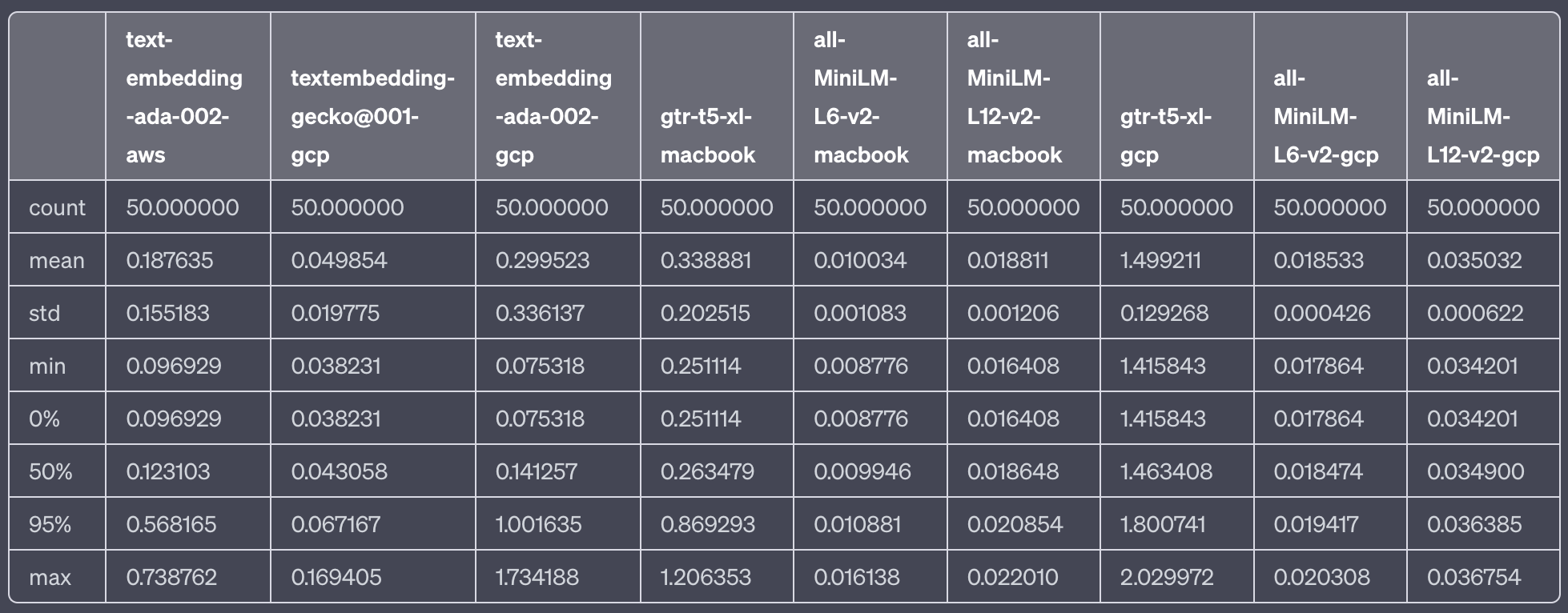
The tests were run from / on the following infrastructure:
- GCP: An n1-standard-4 (4 vCPUs, 15 GB RAM) instance running in us-central1
- AWS: A ml.t3.large (2vcpu + 8GiB) instance running in us-west-2
- My MacBook Pro 14" M1 with 16GB of RAM
For all experiments, pytorch used the CPU only.
Software used:
JupyterLabsentence-transformers 2.2.2pytorch 2.0.1- Python 3.10 and 3.11