The Retrieval Tradeoff: What 50 Experiments Taught Us About Context Engineering


Zep builds temporal knowledge graphs from conversations and business data, then automatically retrieves relevant context when your agent needs it. The goal is straightforward: give agents the information they need to complete tasks, reliably.
But how much context is enough? Retrieve too little and the agent lacks information. It guesses, hallucinates, or fails the task. Retrieve too much and you're burning tokens on noise while latency creeps up. This isn't a theoretical concern. It's a tuning decision every agent builder faces, and it involves a three-way tradeoff:
- recall (did we get everything relevant?);
- precision (is what we got actually relevant?);
- and efficiency (how many tokens, how much latency?).
We ran 50 experiments to quantify this tradeoff. Here's what we learned.
Why This Matters for One-Shot Retrieval
Zep uses one-shot retrieval. We optimize for latency, which means we don't do iterative retrieval loops. There's no "retrieve, realize we need more, retrieve again" pipeline. That pattern works fine for latency-tolerant applications like research or document analysis. It doesn't work for real-time agents in conversation.
Zep uses one-shot retrieval. We optimize for latency, which means we don't do iterative retrieval loops. There's no "retrieve, realize we need more, retrieve again" pipeline. The consequence: for questions requiring multi-hop reasoning, all necessary context must come back in a single pass.
The consequence: for questions requiring multi-hop reasoning, all necessary context must come back in a single pass. Consider a question like "What was the budget we discussed for the project Sarah mentioned last week?" Answering requires connecting three pieces: who Sarah is, which project she mentioned, and what budget was discussed. With one-shot retrieval, all three hops worth of context must arrive together. Miss any link and the chain breaks.
This makes the recall/efficiency tradeoff especially consequential for us.
What We're Retrieving
Zep's knowledge graph stores several types of artifacts. For this article, we'll focus on:
Edges have a fact attribute. Discrete pieces of information extracted from conversations, things like "User mentioned Q2 budget was approved at $50K" or "Sarah recommended switching to the new vendor."
Nodes have entity summaries. Broader context about people, projects, and concepts, including their relationships to other entities.
Given a query, Zep retrieves relevant edges and nodes, assembles them into context, and hands that to the agent. In this series of experiments, the edge_limit and node_limit parameters control how much we retrieve. We varied these limits to see how accuracy, latency, and token usage respond.
Experimental Setup
We used the LoCoMo benchmark: 10 users, 35 conversation sessions each, with questions requiring recall over long conversation history. We ran each configuration 10 times (50 total runs) and used gpt-4o-mini for both the agent and grader, matching what other research groups have published.
A note on LoCoMo: we're not huge fans of this benchmark. It has known issues with question quality and answer ambiguity. But it's small enough to run rapidly and enables comparison with published results. The goal here isn't to claim state-of-the-art (though, we believe these results are SOTA for a production context/memory service). It's to understand how behavior changes across configurations.
Here's what we tested:
| Config | Edge Limit (facts) | Node Limit (entity summaries) |
|---|---|---|
| Minimal | 5 | 2 |
| Light | 10 | 2 |
| Default | 15 | 5 |
| Medium | 20 | 20 |
| Maximum | 30 | 30 |
What We Measured
Accuracy is binary: did the agent produce the correct answer?
Completeness answers a different question: was the retrieved context sufficient to answer correctly? Accuracy alone doesn't tell you why the agent succeeded or failed. An agent can fail despite good retrieval if the model makes a reasoning error. Completeness isolates retrieval quality from model quality.
We use an LLM judge to evaluate each response against the retrieved context:
| Rating | Meaning |
|---|---|
| Complete | Retrieved context contained all information needed to fully answer the question |
| Partial | Context contained some relevant information, but some facts were missing. Context may or may not be adequate to answer question. |
| Insufficient | Context lacked necessary information; agent couldn't answer or had to guess |
Results
Accuracy vs. Context Size
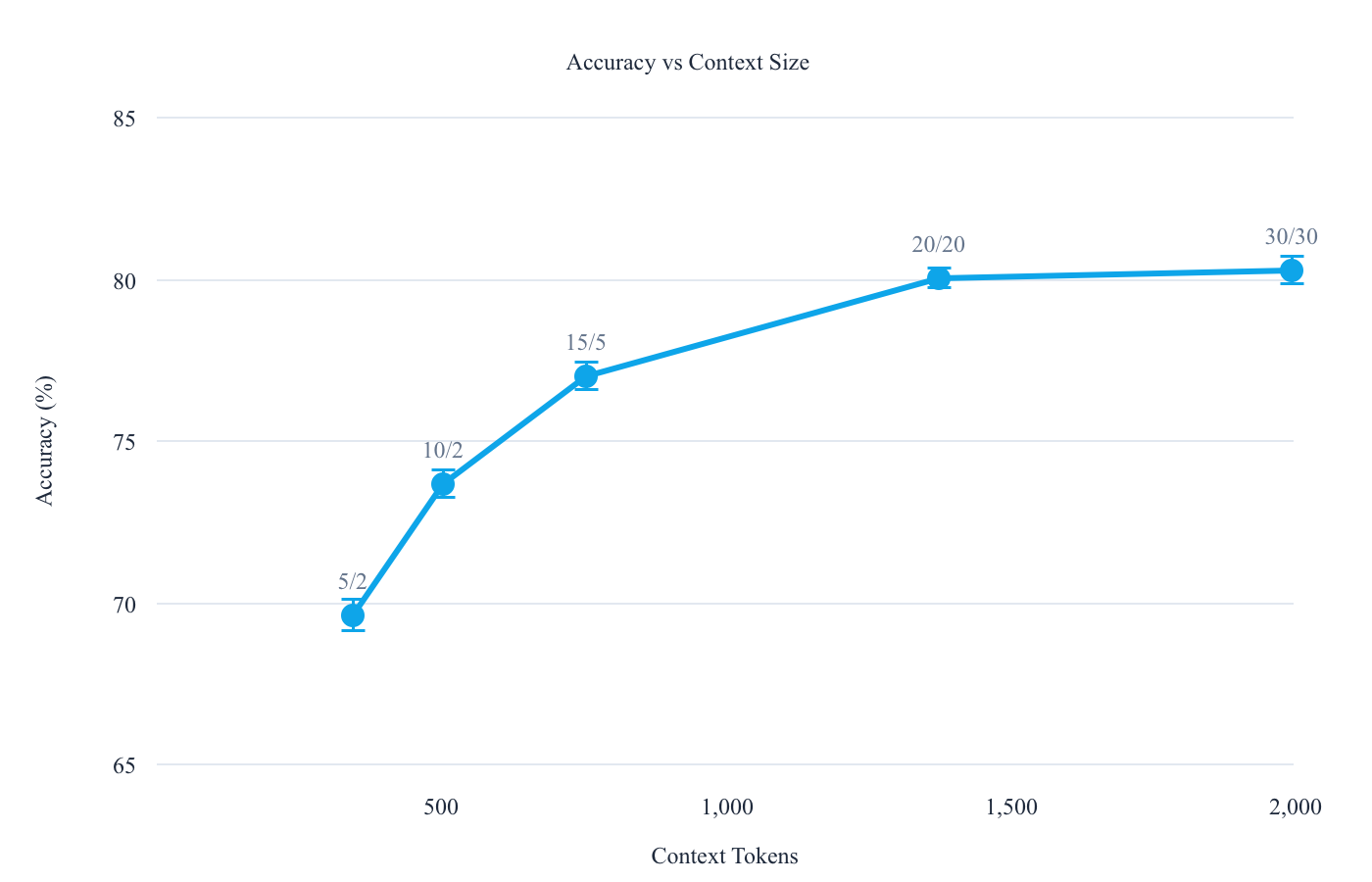
| Config | Accuracy (mean ± std) | Context Tokens |
|---|---|---|
| 30/30 | 80.32 ± 0.43 | 1,997 |
| 20/20 | 80.06 ± 0.33 | 1,378 |
| 15/5 | 77.06 ± 0.41 | 756 |
| 10/2 | 73.72 ± 0.41 | 504 |
| 5/2 | 69.62 ± 0.47 | 347 |
Accuracy vs. Retrieval Latency
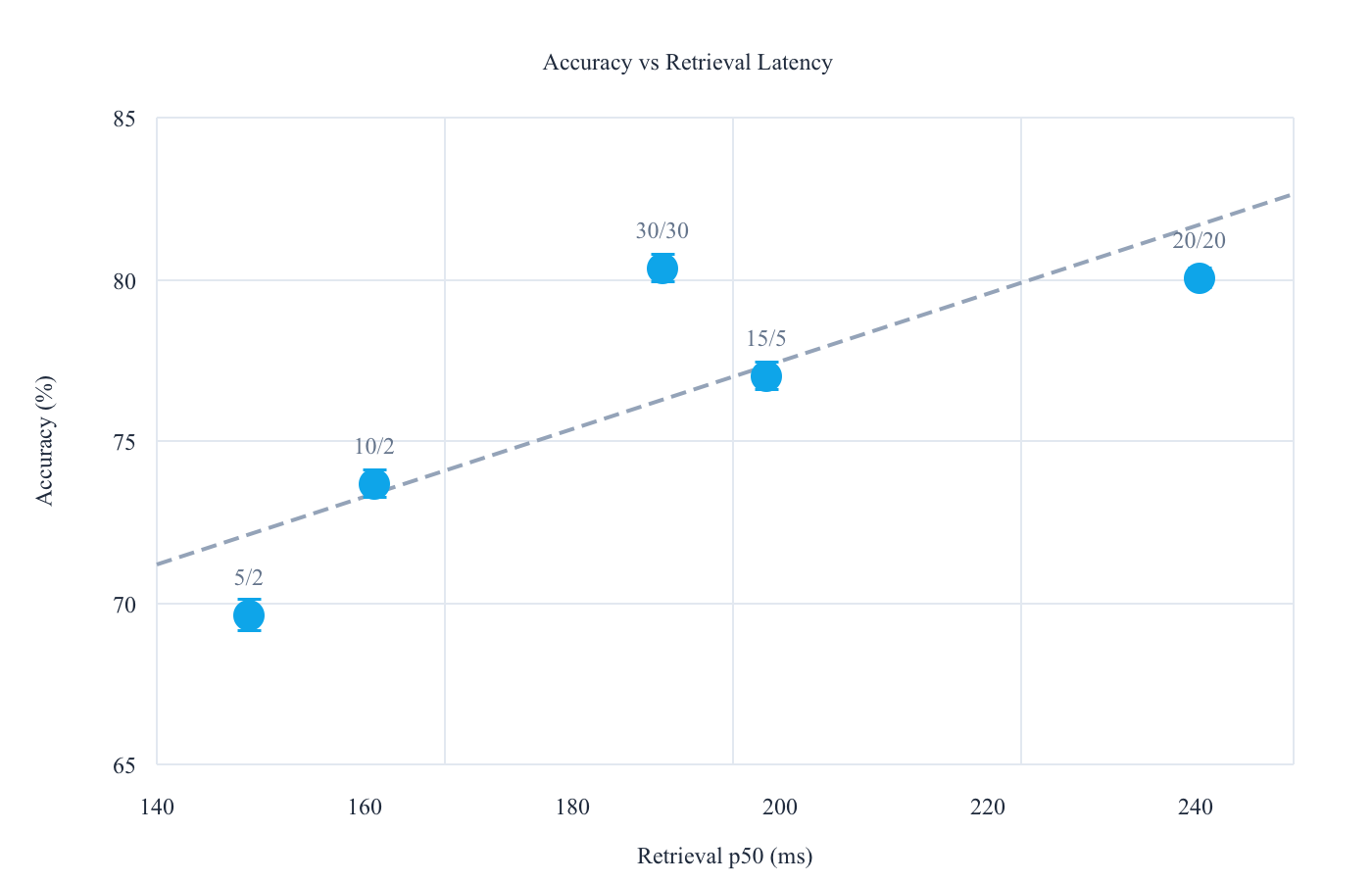
| Config | Accuracy (mean ± std) | Retrieval p50 (ms) |
|---|---|---|
| 30/30 | 80.32 ± 0.43 | 189 |
| 20/20 | 80.06 ± 0.33 | 241 |
| 15/5 | 77.06 ± 0.41 | 199 |
| 10/2 | 73.72 ± 0.41 | 161 |
| 5/2 | 69.62 ± 0.47 | 149 |
Completeness Breakdown
| Config | Complete | Partial | Insufficient |
|---|---|---|---|
| 30/30 | 76.5% | 10.0% | 13.5% |
| 20/20 | 75.8% | 11.0% | 13.2% |
| 15/5 | 70.0% | 13.0% | 16.9% |
| 10/2 | 62.8% | 16.6% | 20.6% |
| 5/2 | 57.4% | 18.9% | 23.8% |
What the Data Tells Us
The diminishing returns curve is clear. Going from 5/2 to 20/20 buys you +10.4 percentage points of accuracy for roughly 4x the tokens. Going from 20/20 to 30/30 buys you +0.26 percentage points for 1.5x the tokens. The curve flattens, but it doesn't invert. More context doesn't hurt accuracy on this benchmark.
Completeness tells a sharper story than accuracy alone. At the minimal 5/2 configuration, nearly 1 in 4 questions (24%) had insufficient context. The agent simply didn't have what it needed. At 20/20, that drops to 13%. At 30/30, it's 13.5%. We've essentially hit the retrieval ceiling for this dataset.
The gap between accuracy and completeness reveals robustness. At 5/2, we see 70% accuracy but only 57% completeness. The agent is succeeding on some questions despite inadequate context: lucky guesses, or questions simple enough to answer without full recall. At 30/30, accuracy (80%) and completeness (76%) track more closely. Tighter correlation means a more robust system.
We've optimized Zep for low-latency use cases such as video and voice agents. Latency stays reasonable across the entire range. Even at 30/30, retrieval p50 is under 200ms. For this dataset and configuration, latency isn't the binding constraint. Context cost and signal clarity are.
Why the Diminishing Returns?
The accuracy plateau around 80% likely reflects a combination of factors, not a single cause:
- Evaluation data limitations. LoCoMo has ambiguous questions and inconsistent ground truth. Some questions simply can't be answered correctly regardless of retrieval quality.
- Model performance ceiling. We used gpt-4o-mini as both the responding agent and the LLM judge. A more capable model might push higher on the same data.
- Zep's retrieval effectiveness on this dataset. There may be relevant facts that our graph construction or retrieval ranking doesn't surface well for certain question types.
This doesn't mean 80% is Zep's ceiling in production. It means LoCoMo stops discriminating beyond this point. Your application, with your data and your questions, is the real test.
Our Retrieval Philosophy
We optimize for recall over precision. The reasoning is straightforward: agents need comprehensive context to make decisions. Missing a critical fact leads to task failure or hallucination. Including tangentially relevant information leads to minor inefficiency, but the agent still succeeds.
The tradeoff we're making: we accept some noise (less relevant facts in the context window) to ensure completeness. For one-shot retrieval, this matters more than in systems that can iterate.
Modern LLMs are good at filtering irrelevant context in their input. They're much less good at inferring facts that aren't there.
The tradeoff we're making: we accept some noise (less relevant facts in the context window) to ensure completeness. For one-shot retrieval, this matters more than in systems that can iterate. You get one chance to assemble context before the agent responds.
Zep's default settings (roughly the 15/5 configuration) balance accuracy with efficiency. We're not trying to minimize context. We're trying to maximize useful context per token.
Tuning for Your Use Case
These parameters are configurable. The data above can help you reason about the tradeoff for your application.
Increase limits when:
- Tasks involve multi-hop reasoning
- Questions span long conversation history
- Stakes are high and missing information means failure
Decrease limits when:
- Queries are simple, direct lookups
- You're operating at scale with cost sensitivity
- Questions are unambiguous and reference recent context
Beyond limits, Zep provides filters (time ranges, entity labels, edge types) that let you narrow retrieval scope without reducing recall on what matters.
The honest guidance: start with defaults, measure your actual task success rate, then tune. Benchmarks tell you about benchmark performance. Your application, with real users asking real questions, is where the tradeoff actually matters.
We've developed an evaluation framework that allows you to easily build evaluations for your own agents and use cases. Give it a spin and let us know what you think.
Wrapping Up
Context engineering is about building the right information environment for your agent. There's no universal "right" amount of context, but there are quantifiable tradeoffs. We've tried to lay them out here.
One-shot retrieval raises the stakes on these tradeoffs. You don't get a second chance to fetch missing facts. Completeness, not just accuracy, tells you whether your retrieval is robust or just lucky.
We've shared our data and methodology. If you run similar experiments on your own workloads, we'd be curious what you find.
Next Steps
- View the LoCoMo experiment code and results.
- Visit the Zep documentation.