What is Context Engineering, Anyway?


Working with large language models reveals an interesting shift in how we talk about making these systems work well. The term "prompt engineering" dominated early discussions, but you'll increasingly hear engineers talking about "context engineering" instead. This isn't just semantic drift. It's a fundamental shift in how we think about deploying LLMs effectively.
I really like the term “context engineering” over prompt engineering.
— tobi lutke (@tobi) June 19, 2025
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
The change has gotten attention from notable industry figures. Tobi Lütke, CEO of Shopify, publicly endorsed the terminology on X (formerly Twitter), emphasizing that the core skill is "providing all the necessary context for the LLM" rather than just crafting clever prompts. Andrej Karpathy has also praised the term, describing context engineering as "the art of providing all the context for the task so that the LLM can solve it."
Context engineering, at its core, is the art and science of assembling all the necessary information, instructions, and tools around a large language model to help it accomplish a task reliably. Unlike basic prompt-tuning, which focuses on crafting clever wording for individual queries, context engineering involves building dynamic systems that feed an AI exactly what it needs, in the right format, to perform consistently across varied scenarios.
+1 for "context engineering" over "prompt engineering".
— Andrej Karpathy (@karpathy) June 25, 2025
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window… https://t.co/Ne65F6vFcf
From Prompts to Context
The early days of working with LLMs like GPT-3 were all about "prompt archaeology": developers would spend hours tweaking the exact phrasing of their prompts, trying to coax better responses through clever wording tricks. Add "Let's think step by step" to get better reasoning. Prepend "You are an expert in..." to invoke domain knowledge. These techniques worked, but they were brittle and didn't scale well to complex applications.
As LLM-powered applications grew beyond simple question-answering demos, a fundamental limitation became obvious: the stateless nature of these models meant they only knew what you told them in each individual interaction. No matter how cleverly you worded your prompt, if the model lacked essential context about the user, the task, or the domain, it would struggle to provide useful responses.
This insight changed how people approached the problem. Harrison Chase defines context engineering as "building dynamic systems to provide the right information and tools in the right format such that the LLM can plausibly accomplish the task." The emphasis here is on systems: not just individual prompts, but entire pipelines that gather, format, and supply relevant context to models at runtime.
📃The rise of context engineering
— Harrison Chase (@hwchase17) June 23, 2025
"Context engineering" has been an increasingly popular term used to describe a lot of the system building that AI engineers do
But what is it exactly?
The definition I like:
"Context engineering is building dynamic systems to provide the… pic.twitter.com/wmAMKpuHU9
The new terminology caught on because it better describes what's actually happening. As Ankur Goyal from Braintrust noted in social media discussions, techniques like Retrieval-Augmented Generation (RAG) are "one flavor of context engineering" rather than separate approaches. This systems-level thinking has become essential as organizations move from experimentation to production deployment of LLM applications. Karpathy's evolution from describing prompting as "vibe coding" to endorsing the more concrete notion of context engineering shows how the field has moved from ad-hoc experimentation to systematic engineering practices.
Context Engineering: A Systems Approach
Context engineering encompasses several key components that work together to create a comprehensive information environment for the LLM:
Dynamic Information Retrieval: Rather than relying solely on the model's training data, context engineering involves fetching relevant information from external sources (knowledge bases, databases, APIs, or real-time data feeds) and incorporating it into the model's context window.
RAG is one flavor of context engineering. For those that say “RAG is dead” hopefully this framing makes it obvious why that’s not the case.
— Ankur Goyal (@ankrgyl) April 20, 2025
Memory Management: For applications that involve ongoing interactions, context engineering includes strategies for maintaining relevant information across conversations while managing the constraints of finite context windows. This might involve summarizing previous interactions, maintaining user preferences, or selectively retrieving relevant historical context.
Tool Integration: Modern LLM applications often need to interact with external systems: running code, querying databases, making API calls. Context engineering ensures these tool outputs are properly formatted and contextualized for the model to use effectively.
Instruction Orchestration: Beyond crafting individual prompts, context engineering involves designing the overall structure of how instructions, examples, and context are presented to the model across multi-step workflows.
Why Context Engineering Matters
To understand why context engineering matters, consider a practical example: building an AI assistant for a legal practice. A naive approach might involve sending the model a contract and asking "Is this fair?" But a context-engineered system would take a much more sophisticated approach.
First, it would establish the model's role and expertise through carefully crafted system instructions. Then it might retrieve relevant legal precedents or standard clauses from a knowledge base. It would incorporate information about the specific client: their business type, risk tolerance, and previous legal issues. The system might also include examples of similar contract analyses to guide the model's reasoning process.
This multi-layered approach to context assembly is what distinguishes production-ready LLM applications from impressive demos. The best-performing systems don't just throw raw information at the model; they construct the entire context window with precision.
The challenge lies in balancing comprehensiveness with efficiency. Too little context leaves the model guessing; too much can overwhelm it or hit token limits. Context engineering requires understanding not just what information to include, but how to structure and prioritize it for optimal model performance.
The User Context Challenge
One of the most compelling applications of context engineering principles is addressing the problem of grounding agents with relevant, up-to-date, and comprehensive user context. This challenge becomes obvious when building AI agents that need to understand users across multiple touchpoints and interactions.
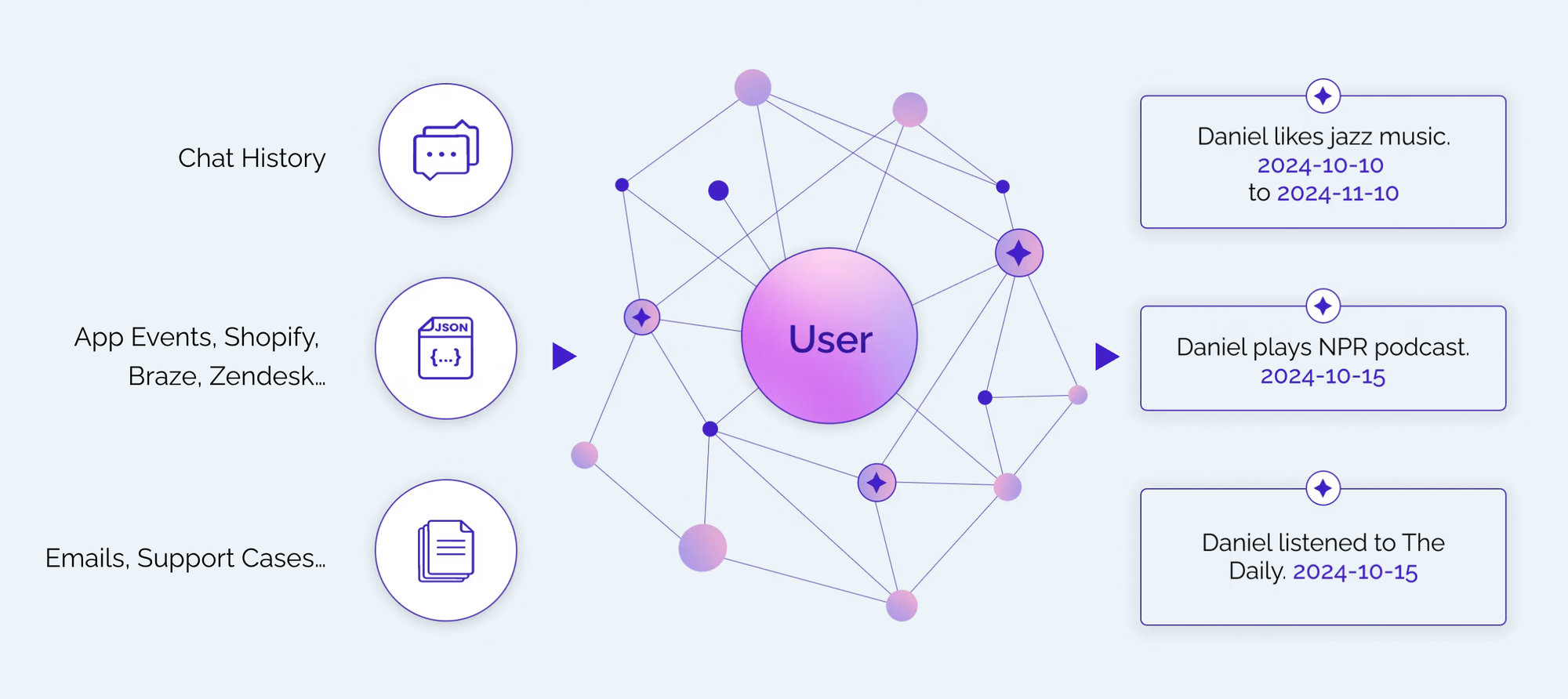
Consider a customer service chatbot that knows you mentioned having trouble with a product in a previous conversation, but has no awareness that you've since returned the item, contacted support via email, or interacted with the company through other channels. The agent operates with a fragmented view of your relationship with the company, leading to repetitive questions and generic responses.
When we started helping developers build AI agents at Zep, we initially focused on what everyone calls "agent memory": basically ensuring agents remember past conversations. But as we worked with more companies deploying agents in production, we realized we were approaching this problem wrong.
The real issue isn't that agents need memory. It's that they have incomplete, fragmented context about users. Companies have dozens of touchpoints with customers: chat conversations, purchase history, support tickets, app usage, email interactions, CRM data. What we call "agent memory" today is really just a set of "facts" extracted from chat history, which for many companies represents a small fraction of what they know about their users.
You could tackle this through agentic tool calling, but that approach often doesn't scale well, adding non-determinism and latency that degrades the user experience.
Our Technical Approach
Rather than treating "agent memory" as simply chat history, we developed a solution that creates unified representations of everything a company knows about a user, continuously updated and temporally aware.
Our approach involves temporal knowledge graphs—dynamic representations that capture not just what's true now, but what was true when, and how information has changed over time. This addresses a core challenge in context engineering: how to maintain accurate, comprehensive context about users whose preferences, circumstances, and relationships evolve over time.
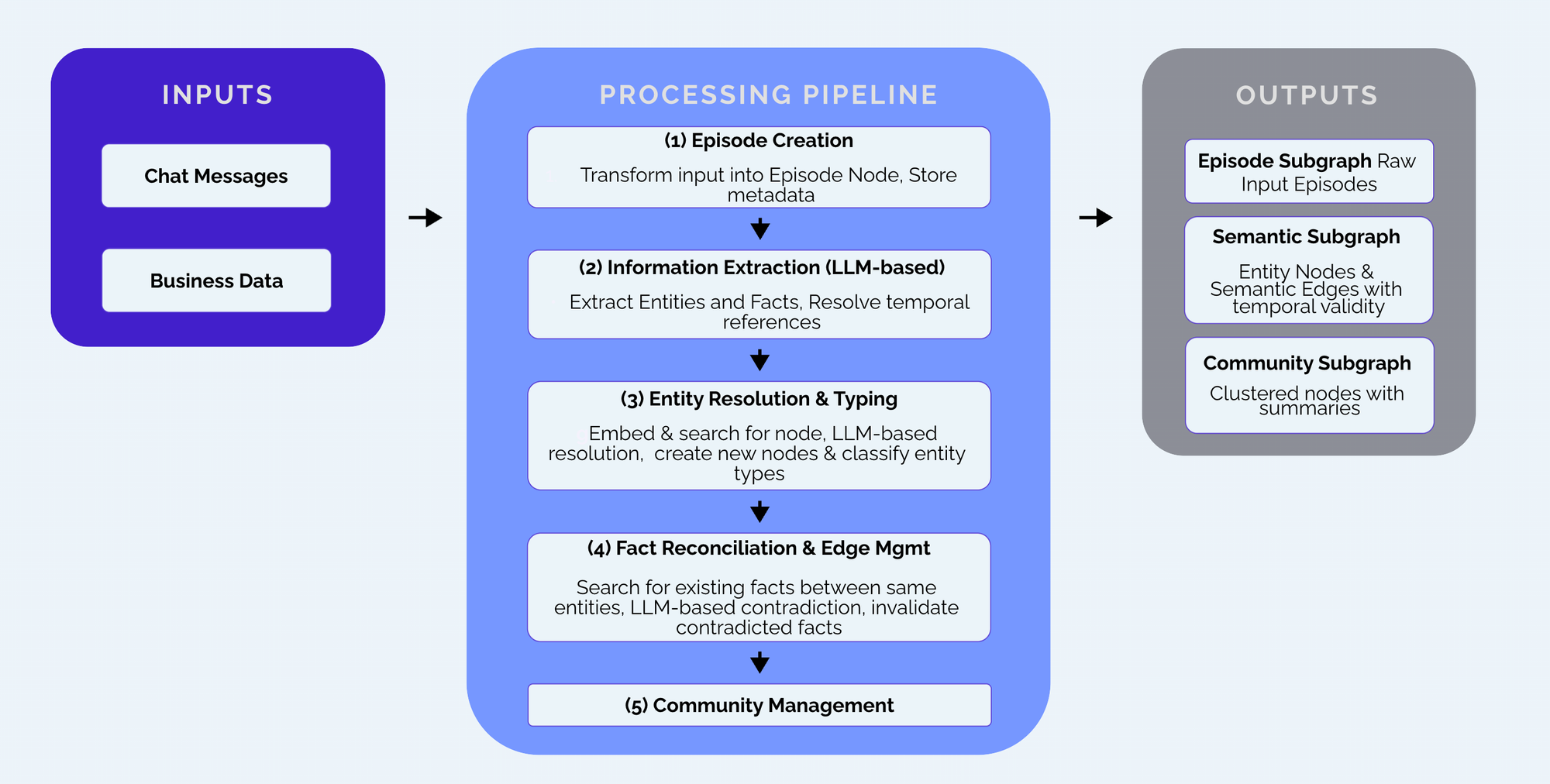
The technical complexity proved significant. Getting LLMs to consistently extract entities and relationships from messy real-world data was much more challenging than working with clean demo data. Real customer data includes misspellings, domain-specific abbreviations, and mid-sentence topic switches that can confuse even sophisticated models.
We observed our system confidently extracting "Netflix," "netflix," and "NETFLIX" as distinct entities, or parsing "my mom Sarah" and "Sarah" as unrelated people. Achieving production-grade reliability required developing reflection mechanisms, comprehensive entity resolution pipelines, and extensive prompt engineering.
Our paper, Zep: A Temporal Knowledge Graph Architecture for Agent Memory, describes in depth the challenges we faced and how we tackled them, including our approach to bi-temporal modeling, entity resolution across data sources, and the architectural decisions that enabled production-grade reliability.
Context Engineering in Practice
The practical applications of context engineering extend across numerous domains, each with specific challenges and requirements:
Enterprise Applications: Companies deploying AI assistants for internal use need systems that can access and synthesize information from multiple business systems: CRM data, support tickets, documentation, and more. Context engineering ensures these systems provide relevant, up-to-date information without overwhelming the model or users.
Automotive: Car manufacturers deploying in-car AI assistants face complex context engineering challenges. The assistant must fuse verbal requests for music, climate control, and navigation with tablet interface interactions, real-time car telemetry, and cloud-stored personal data and subscriptions. When a user says "I'm cold," the system adjusts climate based on current cabin temperature, past preferences, and suggests heated seats if this manufacturer subscription is available.
Educational Technology: AI tutoring systems benefit from context engineering that maintains learner profiles, tracks progress across sessions, and adapts instruction based on individual learning patterns and preferences. We work with Praktika AI, which offers personalized language lessons using AI tutors. Our system enables their tutors to remember user learning preferences, past mistakes, and progress patterns across sessions, creating genuinely personalized education experiences.
Healthcare: Medical AI assistants require careful context engineering to provide relevant information while maintaining privacy and ensuring accuracy. Heal Babycare, which builds AI assistants for pregnant women and new parents, uses our custom entity types for medical conditions, symptoms, and treatment responses. Instead of storing arbitrary facts like "user mentioned headaches," they capture structured HealthCondition entities with fields for severity, frequency, triggers, and treatments.
Multi-Agent Systems and Context Sharing
An important lesson we learned involves context sharing in multi-agent systems. Some developers have attempted architectures where one "manager" agent breaks problems into parts and spawns multiple sub-agents to solve each part in parallel. In theory, this sounds modular. In practice, it often fails due to missing shared context.
Walden Yan from Cognition AI describes an example with a Flappy Bird game clone task. The main agent gave one sub-agent the task of building the game background, and another the task of building the bird character. Each worked independently. The result? One sub-agent designed a Mario-like background; the other created a bird that didn't match the style or mechanics of Flappy Bird. When the "manager" tried to combine them, the pieces didn't fit.
The root cause was that each sub-agent lacked the full context of the original goal and what the others were doing. The solution involves sharing context among agents or, simpler yet, avoiding splitting into multiple independent agents for tasks that require tight coherence.
What's Next
Context engineering is becoming even more critical to the success of LLM applications. While models are getting more capable, the challenge of providing them with the right information at the right time remains fundamentally important.
The emergence of tools and frameworks specifically designed for context engineering—from Zep for building a unified user profile to LlamaIndex for complex retrieval workflows to frameworks such as DSPy—suggests that this is becoming a distinct engineering discipline. We're pushing the boundaries of what's possible in terms of maintaining comprehensive, accurate user context across complex, multi-touchpoint relationships.
The engineers who become skilled at context engineering will build the most effective and reliable AI applications. The real work in AI happens not in the prompt or the model itself, but in everything you feed into the model before it generates a response.
Context engineering shows how our approach to working with large language models has evolved. It's the difference between impressive demos and production-ready systems that users can rely on. As we continue pushing the boundaries of what's possible with AI, the sophistication of our context engineering will largely determine the utility and trustworthiness of the systems we build.
The shift from prompt engineering to context engineering isn't just a change in terminology—it's recognition that building effective AI applications requires the same careful, systematic approach that we apply to any complex software system. The models may be new, but the principles of good engineering remain constant: understand your requirements, design your systems thoughtfully, and ensure your components work together reliably.
To learn more about our approach to building comprehensive user context for agents, visit our documentation or explore our open-source Graphiti knowledge graph engine at https://github.com/getzep/graphiti.