Building A Russian Election Interference Knowledge Graph
How we built a Knowledge Graph-based app for exploring Russian interference in the run-up to the 2024 US elections.


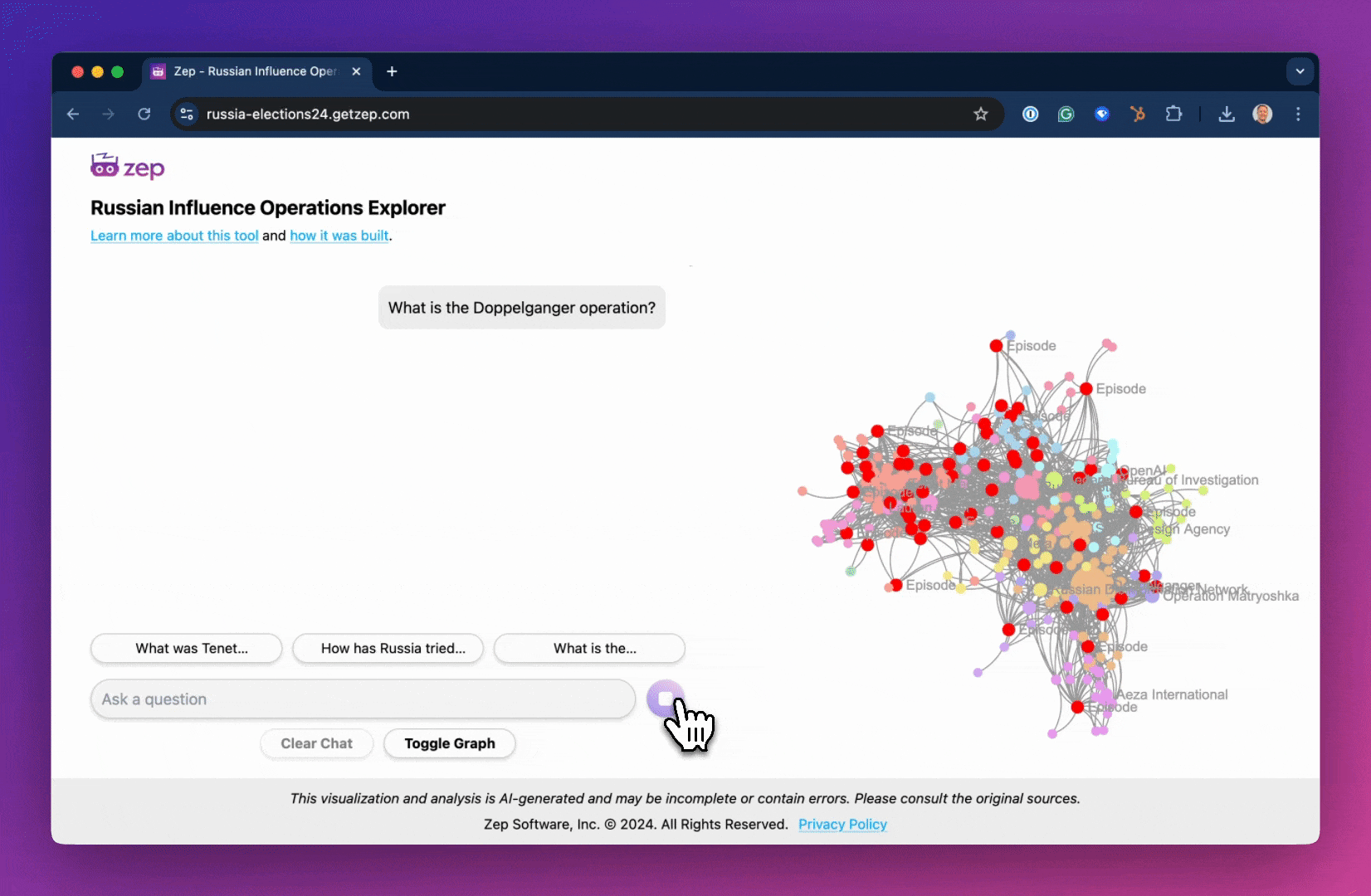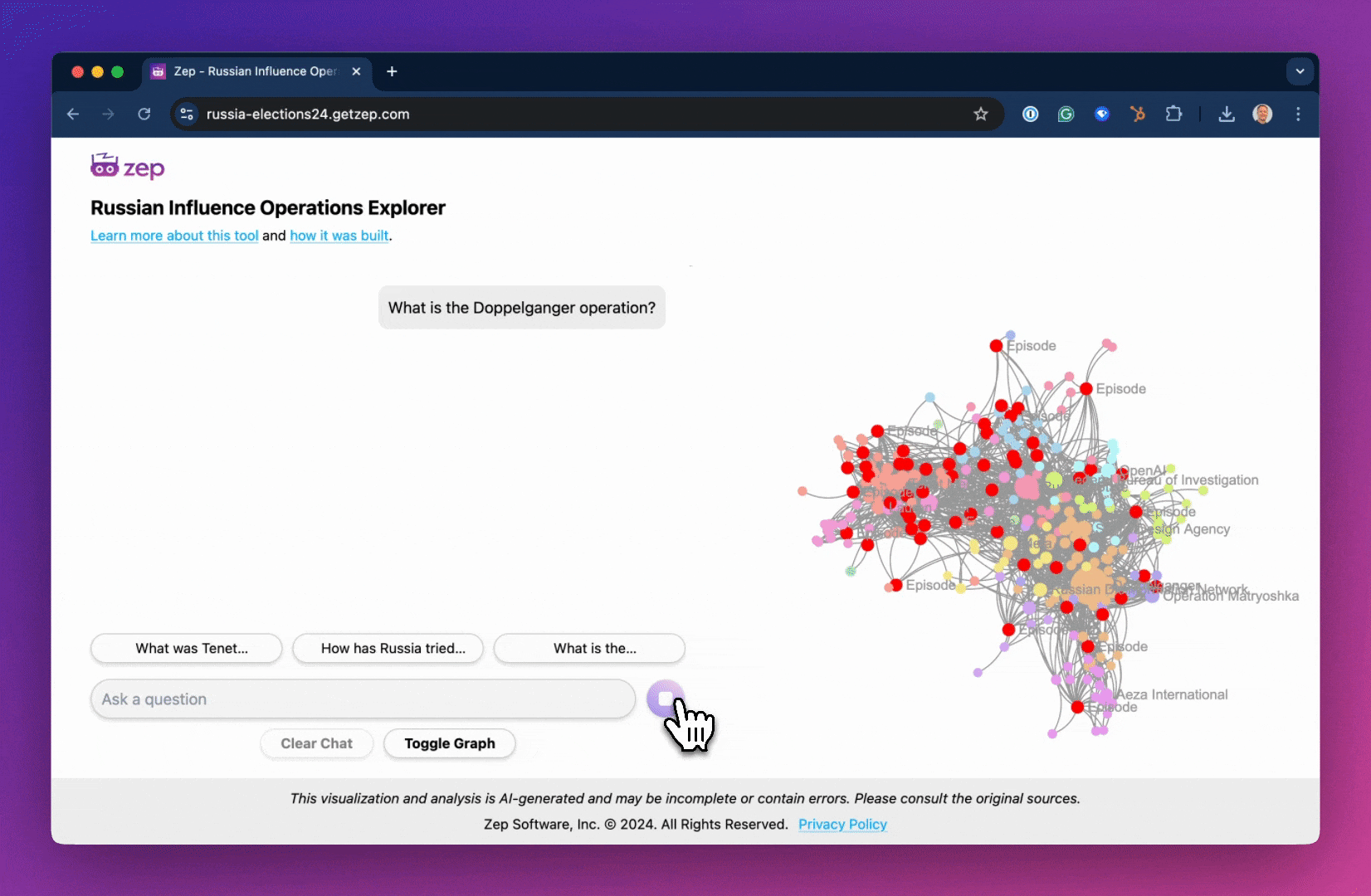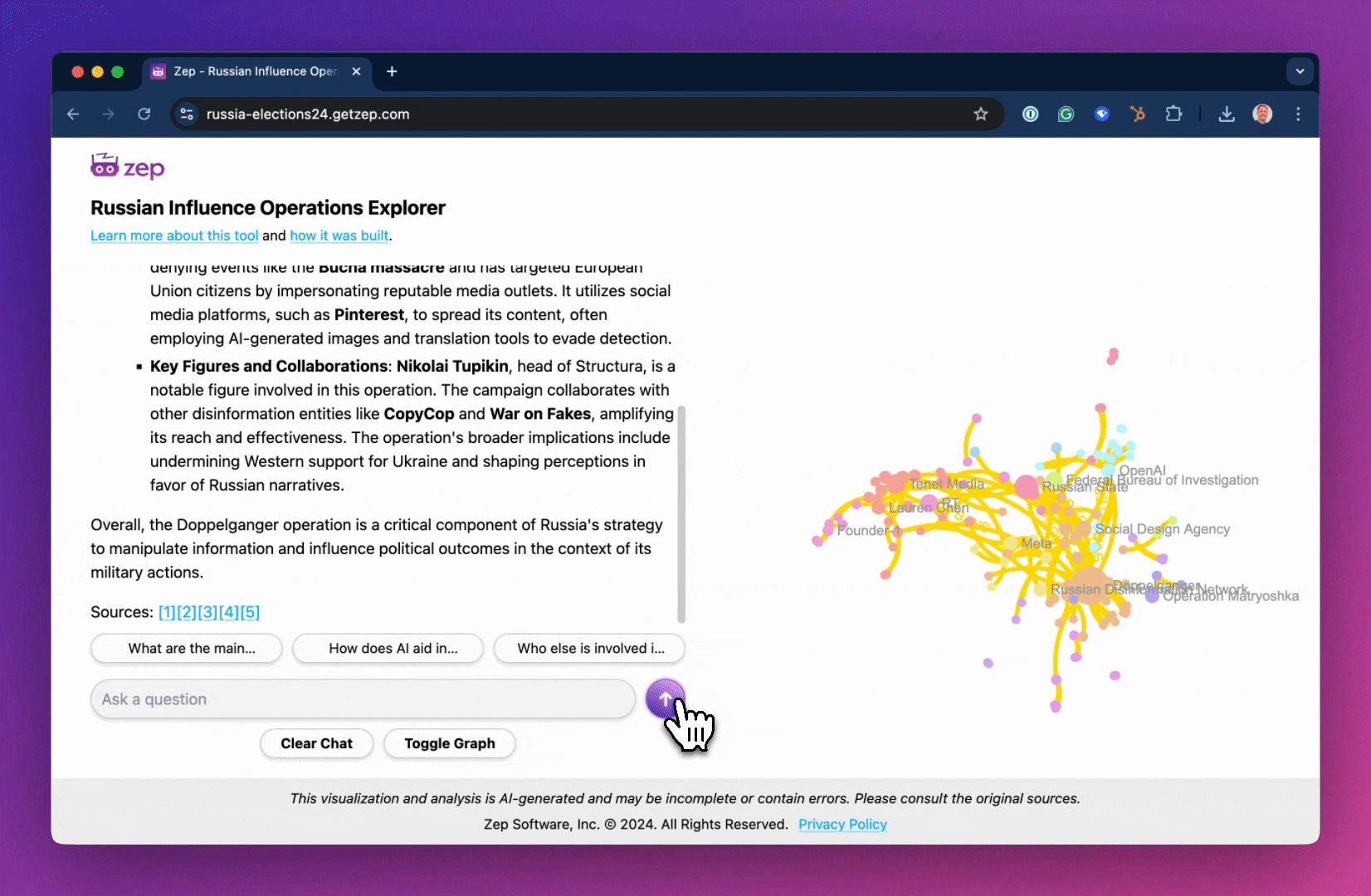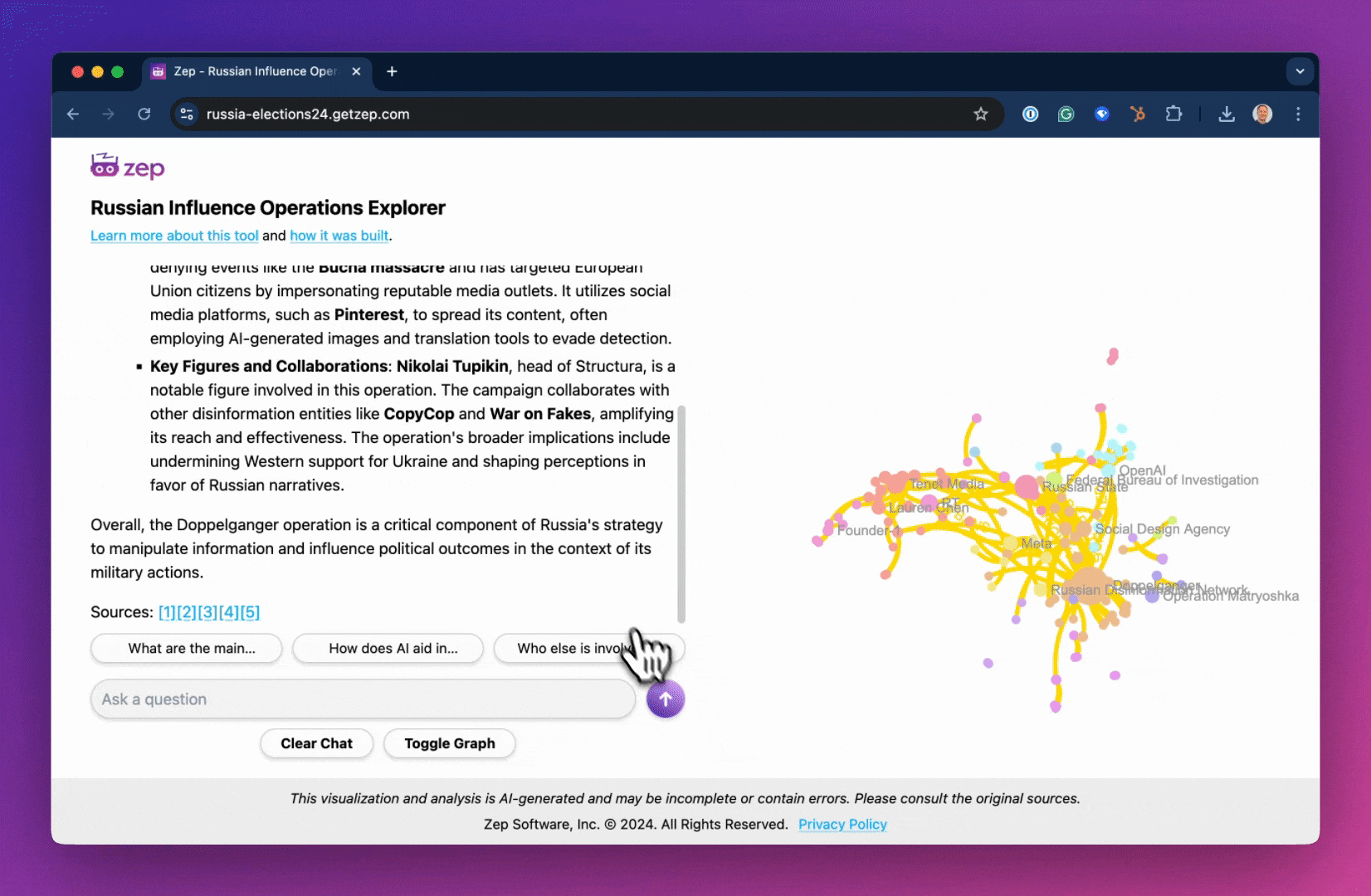
We recently announced our Russian Influence Operations Explorer, a knowledge graph-based visualization and LLM agent for exploring Russian state efforts to interfere in the 2024 US election.
Russia's efforts have been the most sustained, broad, and pernicious among several state actors attempting to influence the election outcomes. They also make for fascinating reading, implicating both innocent US citizens and those allegedly not so innocent. Given the number of actors involved and their web of relationships, a knowledge graph is useful for representing this universe.
The Explorer's knowledge graph was built using Graphiti, the open-source Knowledge Graph library at the core of Zep's memory layer for AI agents. Graphiti autonomously builds dynamic, temporally-aware knowledge graphs representing complex, evolving relationships between entities.
Getting the Q&A agent to respond to questions in an unbiased but thorough way was challenging, particularly when using smaller, faster models such as gpt-4o-mini. So, too, was data cleansing and ingestion. This technical deep-dive examines the architecture and implementation of the Explorer application, with a particular focus on key design decisions and how we leveraged Graphiti, LangChain, and LangGraph throughout. The guide provides detailed insights into our development process and architectural choices.
We'll cover:
- The Graphiti Data Pipeline
- Knowledge Graph Architecture
- LangGraph Agent Implementation
- Building the FastHTML application
Exploring the Doppelganger Operation
The Graphiti Data Pipeline
Data sources included media articles, U.S. and foreign government documents (e.g., Department of Justice indictments), and non-governmental entities (e.g., OpenAI, Microsoft). The dataset comprised approximately 50 documents in PDF format and web pages.
As with many data projects, data cleaning is a fiddly and quite iterative task. We spent at least 40% of our time on this project on this task, with plenty of manual inspection of input data and the resulting graph.
Graphiti supports the ingestion of both unstructured text and structured JSON data. To transform our source documents into unstructured text suitable for Graphiti ingestion, we leveraged LangChain's UnstructuredPDFLoader and UnstructuredURLLoader.
A Graphiti Episode is a unit of ingestion from which nodes and edges are extracted. An episode is itself a node, connected by edges to each node identified in the ingested data. Episodes enable querying for information at a point in time and understanding the provenance of nodes and their edge relationships.
Chunking articles into multiple Episodes improved our results compared to treating each article as a single Episode. This approach generated more detailed knowledge graphs with richer node and edge extraction, while single-Episode processing produced only high-level, sparse graphs.
loader = UnstructuredURLLoader(
urls=[url],
mode="elements",
chunking_strategy="by_title",
combine_text_under_n_chars=COMBINE_TEXT_UNDER_N_CHARS,
max_characters=MAX_CHAR_PER_CHUNK,
post_processors=doc_cleaners,
)Getting the right chunks also took experimentation. We split chunks semantically, using document titles as boundaries. We also needed to combine smaller texts into larger chunks and fix several parsing issues from HTML and PDF text extraction and document OCR. Unstructured's out-of-the-box cleaners worked well for this.
In the past, we've found that chunking documents often results in chunks that are out of context with the whole document, making Graphiti's task of building a knowledge graph fairly difficult. To address this issue, we used a neat trick recently written about by Anthropic. We asked an LLM to situate each chunk within the document and prepended this context to each chunk.
async def claude_generate_chunk_context(
chunk: str,
text: str
) -> str:
"""Given a chunk and a text, return a context for the chunk"""
response = await anthropic_client.beta.prompt_caching.messages.create(
model="claude-3-5-haiku-20241022",
max_tokens=2048,
system=[{
"type": "text",
"text": f"""<document>
{text}
</document>""",
"cache_control": {
"type": "ephemeral"
},
}],
messages=[{
"role": "user",
"content": f"""
Here is the chunk we want to situate within
the whole document:
<chunk>
{chunk}
</chunk>
Please give a short succinct context to situate
this chunk within the overall document for the
purposes of improving search retrieval of the
chunk. If the document has a publication date,
please include the date in your context. Answer
only with the succinct context and nothing else.
"""
}]
)
logger.info(response)
return response.content[0].textSituating each chunk within the document
Graphiti extracts and maintains temporal metadata such as valid_at and invalid_at dates indicating whether a fact representing an edge relationship is still valid given newer information. To ensure we were capturing valid_at dates, nodes extracted from each chunk, it was important to ensure the chunk context contained article or document dates. We did this via our prompt.
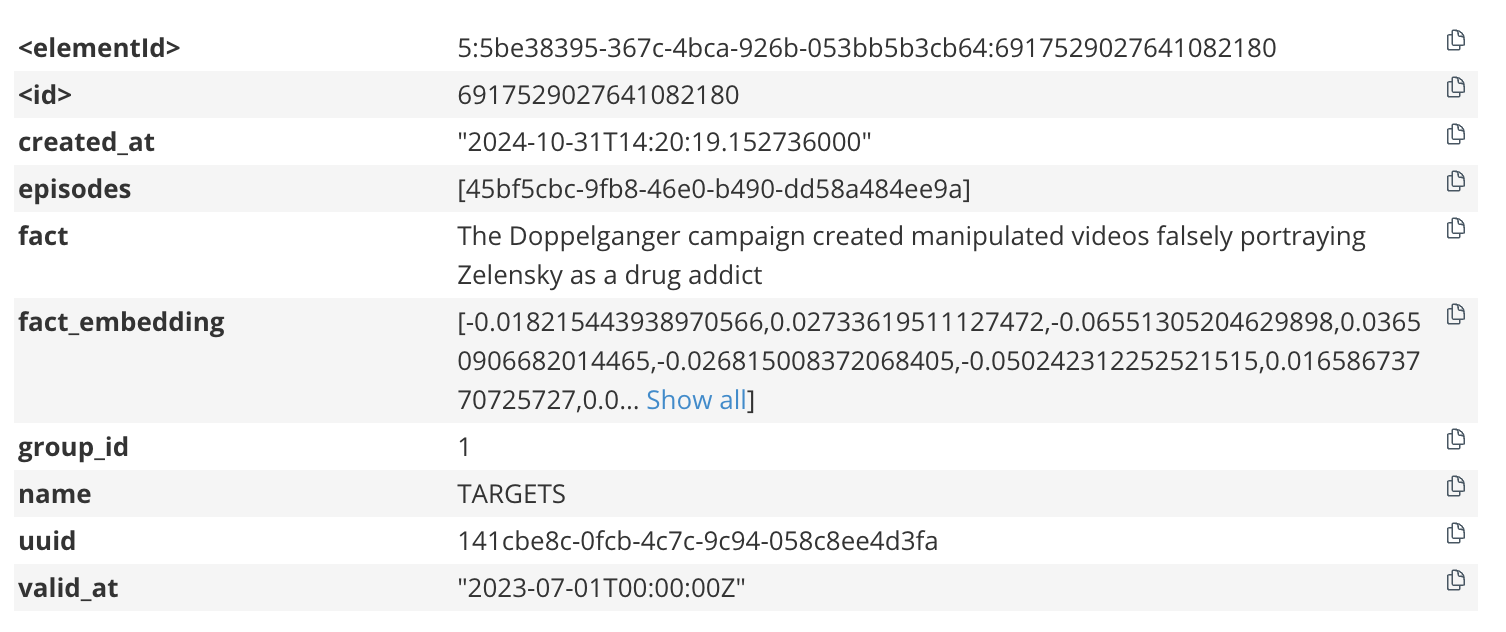
valid_atTemporal Metadata on an EdgeFor large documents with many chunks, contextualizing each chunk can be expensive and slow. Each prompt needs a copy of the entire source document. In the code above, we use Anthropic's prompt caching, which allows us to cache the document tokens for each large document, significantly reducing inference time and cost.
We've identified data chunking as a future enhancement for Zep's implementation of Graphiti. Chunking is challenging to generalize, so we're not convinced it makes sense to build it directly into the Graphiti library.
async def ingest_graph_data(client: Graphiti, docs: list[Document]):
for i, doc in enumerate(docs):
await client.add_episode(
name=doc.metadata.get("source", f"source {i}"),
episode_body=doc.page_content,
source_description=doc.metadata.get("title", f"source {i}"),
reference_time=datetime.now(),
source=EpisodeType.text,
group_id="1",
)Ingesting chunks into Graphiti
After generating the chunks, we added them as episodes to Graphiti's graph. We passed the document's URL as the episode's name, allowing us to retain data provenance for extracted entities.
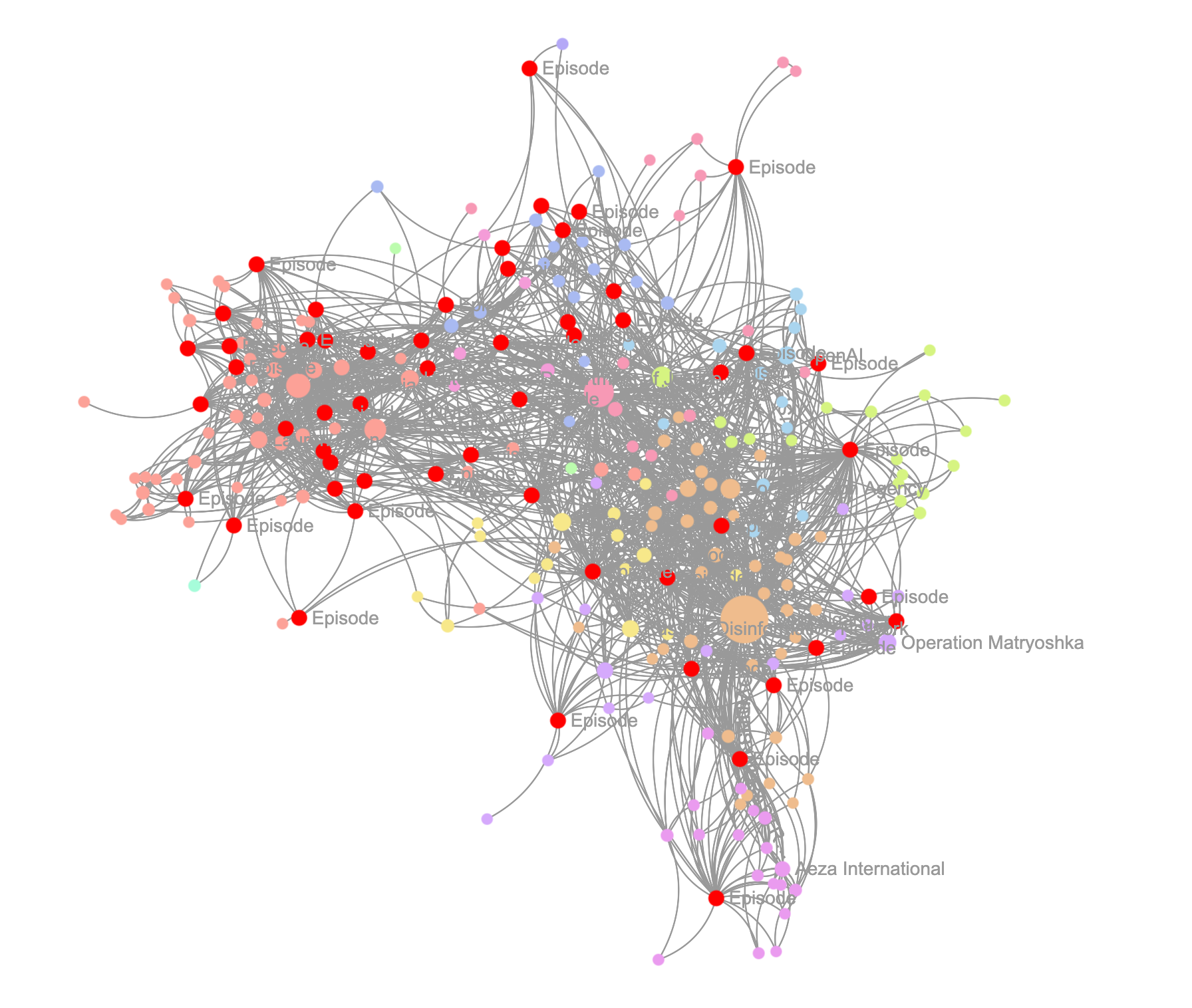
In the Explorer's graph visualization, Episodes are represented by red nodes, while other nodes are color-coded by their respective communities. Interactive hover functionality allows users to inspect the data contained within any node or edge.
Russian FSB in Moscow directs influence operations in the US through multiple channels, including alleged collaboration with RT's deputy editor-in-chief and Burlinova, who was charged as an illegal Russian agent for her work with PICREADI and Meeting Russia program. The FSB officer also worked with RaHDit on developing cyber tools.Community Summary
Graph communities are densely connected subgroups of nodes within a network where connections between members of the same community are more frequent than connections to nodes outside the community. Graphiti uses community detection algorithms to identify these natural clusters by analyzing the network's structure and connection patterns. Graphiti generates summaries for these communities, providing a useful overview of larger graph sections.
Building the Assistant
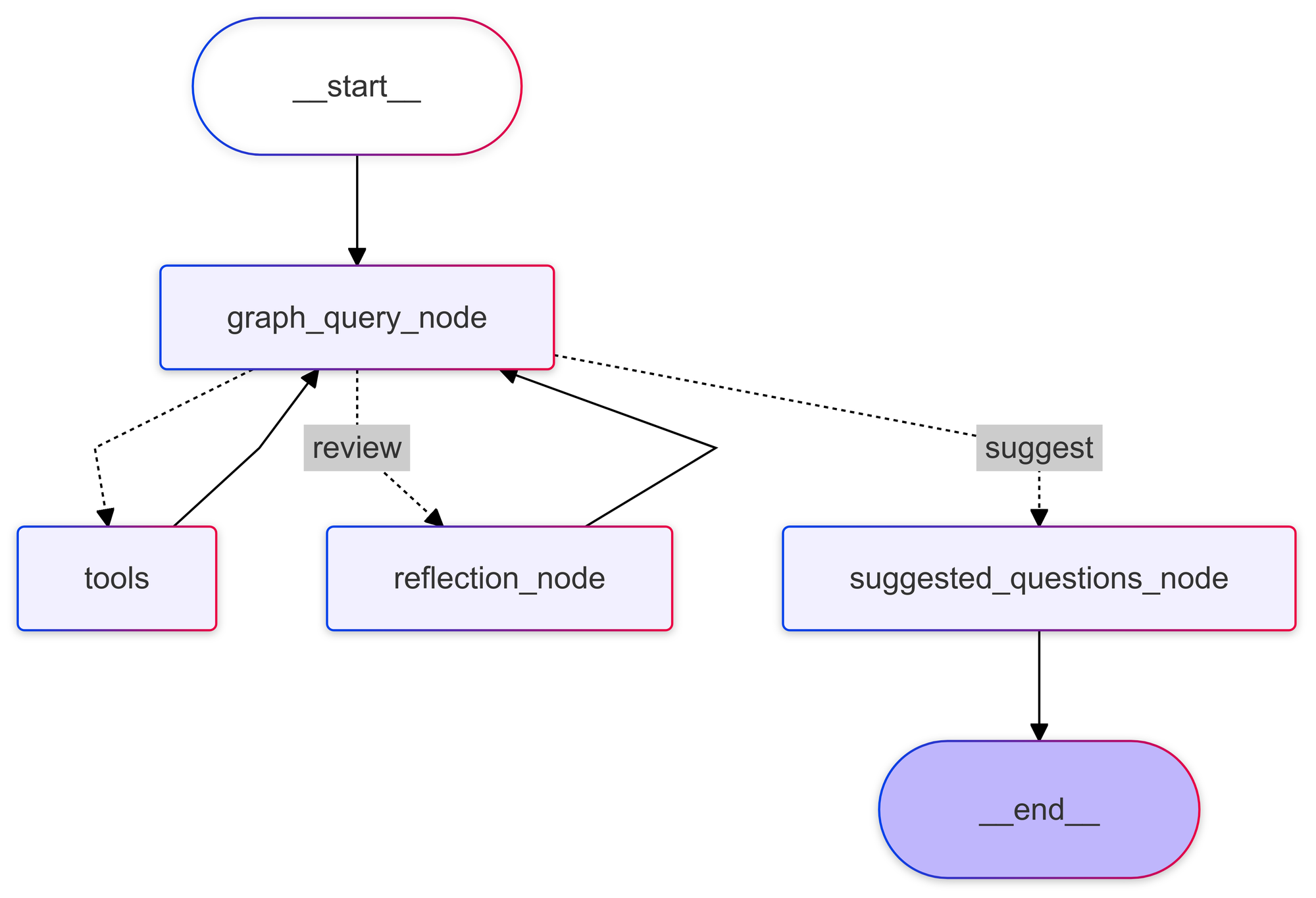
We built the Explorer's chat assistant using LangGraph, LangChain's new agent framework. The agent is intentionally simple, with four main nodes:
- A
graph_query_nodethat processes user messages - A
graph_tools nodethat uses Graphiti to query the knowledge graph - A
reflection_nodethat critique's the response from thegraph_query_node, ensuring responses are accurate, complete, and relevant. - A
suggest_questions_nodethat generates contextually relevant questions that we offer users as suggested next steps in their exploration.
Addressing agent inaccuracy and incompleteness (and trying not to be blamed for bias)
When using smaller, faster models, such as gpt-4o-mini, we received incomplete or misfocused answers to questions despite the tool results containing adequate context to respond accurately and completely.
Even worse, we saw numerous responses in which implication, complicity, and causality were inverted or spurious. For example, implying that a national television network was working directly with Russia to spread disinformation, when their programming was rather reported to have been manipulated or impresonated. This was particularly problematic given the sensitive nature of our application.
We decided to add a single reflection step, where the output from the graph_query_node was reviewed and critiqued. The node would then be allowed to update its output. This significantly improved the quality of response, though we still see some inaccuracy at times and believe additional iterations may be helpful. This would come at the cost of latency: two additional LLM calls per iteration.
reflection_prompt = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=f"""You are a reflection agent
that evaluates responses for:
1. Factual accuracy based on provided
context. In particular, ensuring
that the response is clear as to
implication, complicity, and
causality.
2. Completeness of answer, including
providing specific examples when
available.
3. Relevance to the original question
Today's date is {today_date}.
""".format(today_date=today_date)
),
MessagesPlaceholder(
variable_name="messages"
),
HumanMessage(
content="""Provide a critique of the
response to be used by the agent to
revise the response.
Focus on accuracy, completeness,
examples, and relevance of the answer
to the question.
Keep the feedback concise and to the
point. Do not exceed 2 short
paragraphs."""
),
]
)The reflection_node prompt
Searching the graph without learning a new language
Graphiti enables us to search the graph without our agent needing to understand a graph query language like Cypher or Gremlin. We can execute sophisticated search pipelines across graph nodes, edges, and communities with a single search tool.
episode_mentionsconfig = SearchConfig(
edge_config=EdgeSearchConfig(
search_methods=[
EdgeSearchMethod.bm25,
EdgeSearchMethod.cosine_similarity,
],
reranker=EdgeReranker.episode_mentions,
),
node_config=NodeSearchConfig(
search_methods=[
NodeSearchMethod.cosine_similarity,
NodeSearchMethod.bfs,
],
reranker=NodeReranker.cross_encoder,
),
limit=10,
)
r = await graphiti_client._search(
query,
config=config,
)Avoiding an LLM call to translate a natural language query into a query language reduces latency and, in our experience, improves the quality of agent results.
Given the diverse results returned from our multi-entity search, the final step in our pipeline is a cross-encoder reranker. We use Voyage's rerank-2 model, which has a large context window, low latency, and we've found to perform very well.
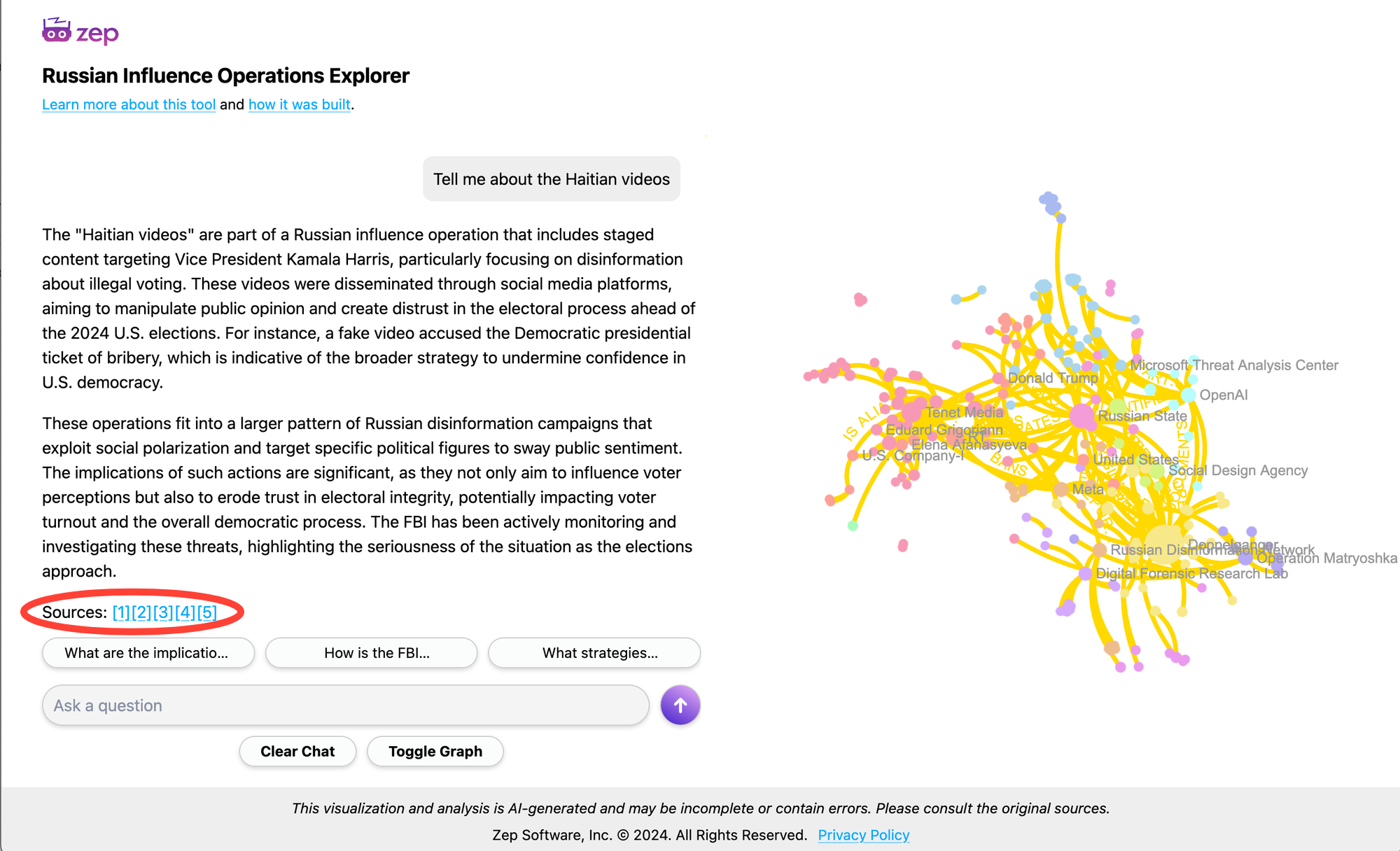
When providing an answer, we aimed to identify related nodes and edges in the graph and to compile a list of sources. Since we had linked the URL of each source to an Episode, we could navigate the graph to find each node's corresponding Episode and retrieve the URL. Given the large number of results, it wasn’t practical to include every source in the list. Instead, we used the graph to rank the Episodes most closely connected to the entities identified in the search. We selected the top five Episodes, reasoning that these source documents best described the answer.
Putting everything together with FastHTML
Using FastHTML front end for our backend and Sigma.js for graph rendering, we put together a nice, clean UI with this architecture:
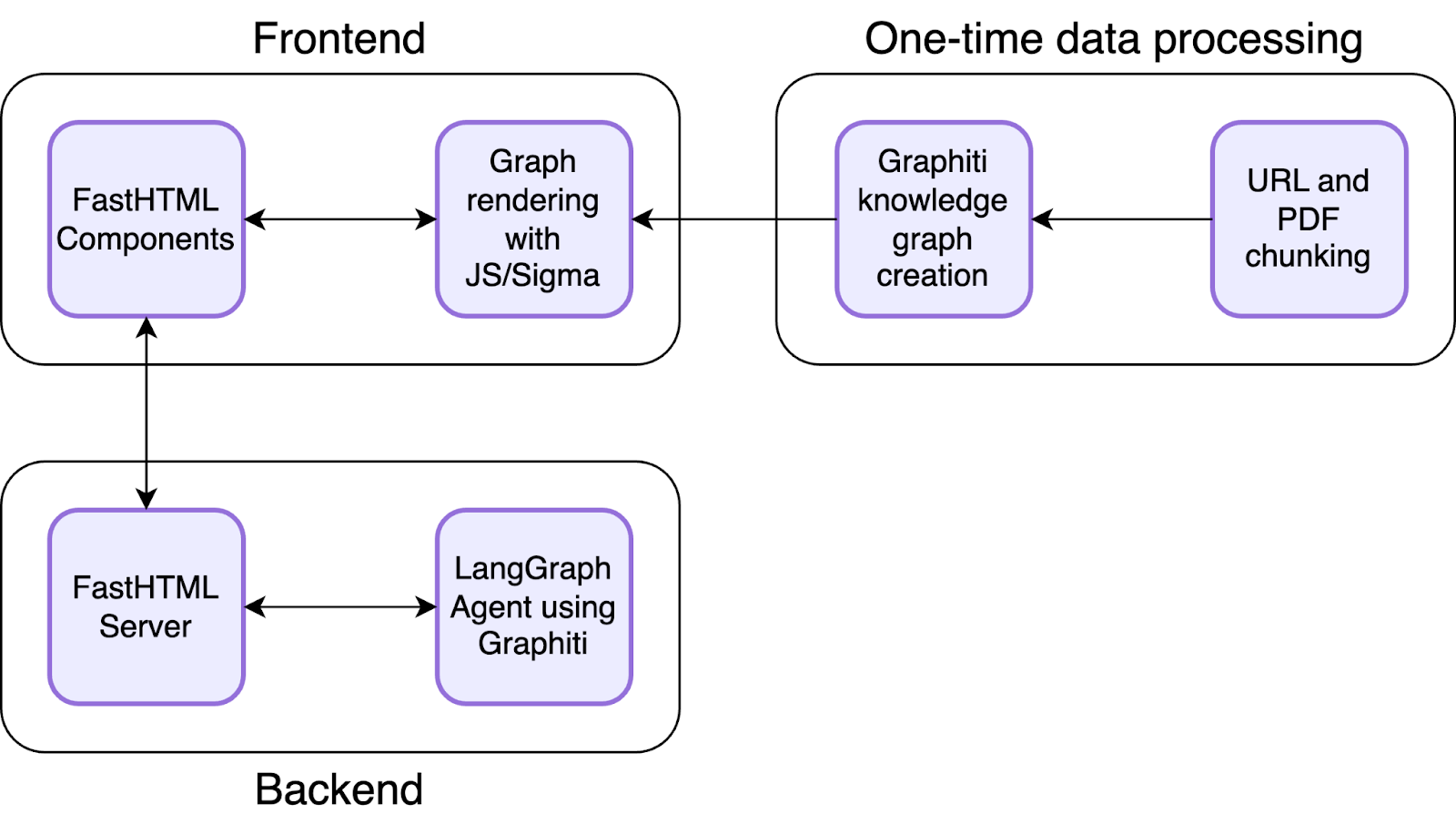
Most of it was pretty straightforward - we just used HTMX swaps to keep the front end in sync with what the back end was doing. We did have to wrangle with some FastHTML quirks, like storing message history and state in Hidden() components. The trickiest bit was selecting and highlighting the edges and nodes referred to in the chat conversation. We did this by hooking into HTMX's out-of-band swap events with an event listener and swapping out a dataset whenever the assistant responded with an answer.
Next Steps
- Visit the Explorer Application.
- View the Explorer announcement, which includes a list of sources.
- Read more about Graphiti.