Context You Can Trace, Filter, and Trust
Every fact in your agent's context graph came from somewhere. Zep's provenance architecture traces facts back to their source data — and lets you filter retrieval by origin.


Key Takeaways
- Zep maintains data provenance as a structural property of the graph: every fact and entity links back to the episode it came from, automatically.
- Provenance matters three ways: an audit trail for regulated industries, a debugging path from an agent's response back to its source data, and a vocabulary the agent itself can filter on.
- Episode metadata projection means you tag a source once at ingestion (system, department, verification status) and that metadata follows onto every fact and entity derived from it.
- It works in both directions: trace any fact back to its origin, or scope an agent to authoritative sources (verified EHR records, excluding unverified chat) at retrieval time, without deleting anything.
Every piece of context in your agent's graph came from somewhere. Zep maintains provenance as a first-class property — so when your agent acts unexpectedly, you can trace its context back to the source.
Agents pull context from many sources (CRM records, support tickets, billing systems, clinical notes, chat history), sometimes all at once, for a single response. Context engineering is what makes agents useful. But it creates a fundamental question: where did this context come from?
That question is data provenance: understanding how data got to the state it's in. When an agent pulls context from multiple sources, provenance is what lets you (and the agent itself) understand where that context originated.
Zep's context graphs were designed with provenance as a first-class architectural concern. Because Zep ingests business data, documents, and structured records alongside chat messages, that provenance spans every type of data your agent reasons over. Here's how it works.
Why Provenance Matters
Most agent memory products treat memory as purely conversational. They store and recall context from chat messages. But production agents need context from CRMs, EHR systems, billing platforms, knowledge bases, internal documents, and more. Zep is designed to ingest data from any source, building a unified context graph from every one.
That's powerful, but it means the graph synthesizes data from many origins into unified entities, relationships, and facts. Synthesis obscures origin. When a fact in the graph says "Patient has a penicillin allergy," did that come from the EHR intake form? A lab report? A nurse's note from three years ago? A message the patient typed into a chatbot?
Provenance matters in three ways:
For regulated industries, it's a compliance requirement. Healthcare, financial services, and legal all need automated decisions to have an auditable trace of what information informed them and where it originated. Without provenance, agents in these industries can't be deployed with confidence.
For any agent builder, it's a debugging tool. When your agent gives an unexpected or incorrect response, the first question is always "what context did it use?" Provenance turns that from a black box into an inspectable chain: response → retrieved facts → originating source data. This makes building, debugging, and iterating on agents faster and more predictable.
For the agent itself, provenance metadata becomes a vocabulary it can reason over: filtering, prioritizing, or weighing context based on where it came from. More on this below.
Most context systems don't track provenance. Zep does. It's a structural property of the graph, not an afterthought.
How Zep Tracks Provenance
Every piece of data ingested into Zep, whether through business data ingestion, chat messages, or batch imports, is stored as an episode. Episodes are the raw, non-lossy record of everything that enters the system. They are never discarded.
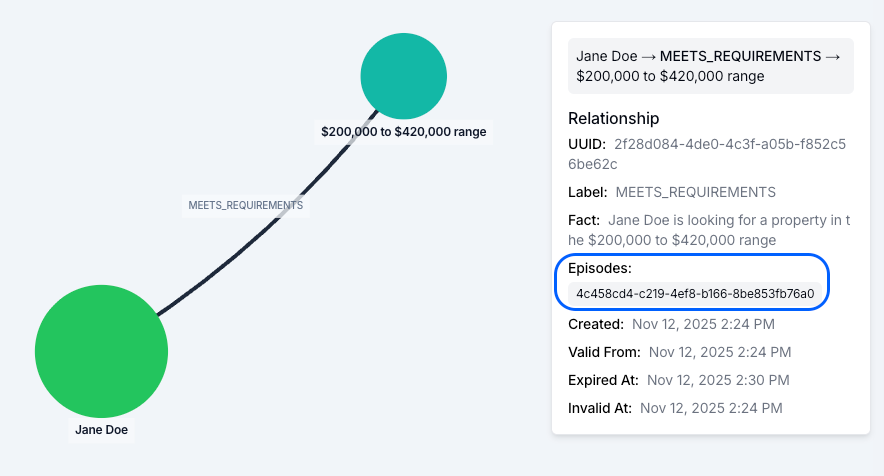
When Zep processes an episode, it extracts entities (nodes) and facts (edges) and integrates them into the context graph. Critically, nodes are connected to the episodes they were derived from, and edges list every episode implicated in their creation. This provenance relationship is automatic. Developers don't need to configure or maintain it. It's a structural property of the graph.
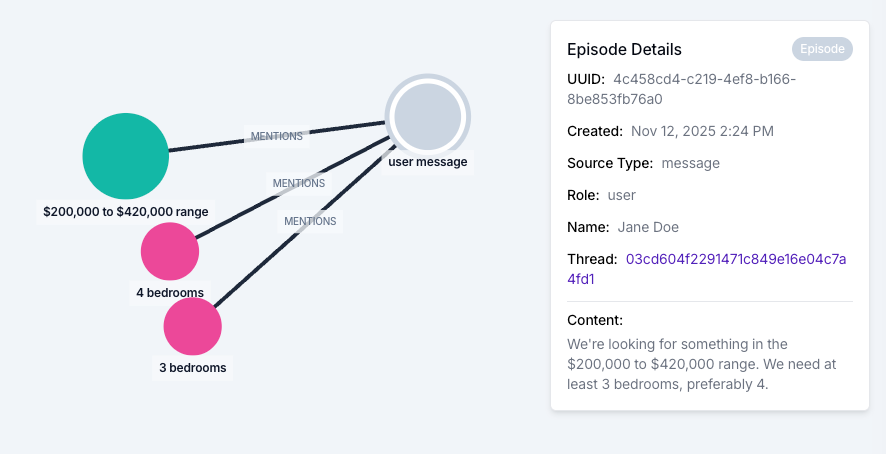
Let's make this concrete. Imagine a healthcare application where a patient's context graph has been built from multiple data sources: EHR records, lab reports, and chatbot conversations. An agent retrieves context to assist a clinician, and one of the facts returned is:
"Patient has a penicillin allergy" (valid from 2024-03-15 — present)
Because Zep maintains episode-to-fact links, you can trace this fact directly back to the episode that produced it: a JSON record ingested from the hospital's EHR system:
{
"patient_id": "pt_5678",
"allergy": "penicillin",
"severity": "severe",
"confirmed_by": "Dr. Martinez",
"confirmed_date": "2024-03-15"
}The provenance chain is intact: the agent's retrieved context traces back through the graph to the originating episode and its raw source data. For every piece of context in the graph, you can answer "where did this come from?" and "how did this data get to the state it's in?"
Episode Metadata Projection
The episode-to-fact link tells you which source produced a piece of context. But it doesn't tell you what system that source came from, what department produced it, or how it should be classified. That's where episode metadata completes the provenance picture, and where Zep's architecture does something worth understanding in detail.
When adding data to Zep, you can attach key-value metadata to each episode: custom attributes that describe where and how the data originated. You define the keys and values that matter for your domain. A healthcare application might tag episodes by source system and verification status. A financial services application might tag by data provider and compliance tier. The schema is yours.
from zep_cloud.client import Zep
import json
client = Zep(api_key=API_KEY)
# Ingest the allergy record with provenance metadata
allergy_data = {
"patient_id": "pt_5678",
"allergy": "penicillin",
"severity": "severe",
"confirmed_by": "Dr. Martinez",
"confirmed_date": "2024-03-15"
}
client.graph.add(
user_id="pt_5678",
type="json",
data=json.dumps(allergy_data),
metadata={
"source": "ehr_intake",
"system": "epic_ehr",
"department": "primary_care",
"classification": "phi",
"verified": True
}
)Now the provenance chain is complete: the agent's context traces back to the originating episode, and the episode's metadata confirms it came from an EHR intake form, in primary care, via the Epic system, classified as PHI, and clinician-verified.
Here's the key architectural property: episode metadata projection. Because facts and entities in the graph link back to their originating episodes, metadata tagged at ingestion time effectively projects through the graph onto every derived node and edge. You tag the episode once; the provenance follows the data wherever it goes in the graph.
This is what makes source-filtered retrieval a natural consequence of the architecture rather than a separate feature bolted on top.
Source-Filtered Retrieval
Once your episodes carry provenance metadata, you can filter context by its source at retrieval time. Because every fact in the graph links back to its originating episode, and every episode carries metadata, you can tell Zep: return context originating from these specific sources.
Continuing our healthcare example: the patient's graph contains facts derived from verified EHR records, lab reports, and informal chatbot conversations. When a clinical agent is assisting with a medication recommendation, you want it grounded in clinician-verified medical records, not unverified patient self-reports.
Episode metadata filtering restricts graph search results to facts derived from episodes matching specific metadata predicates, using AND/OR logic with nested filter groups.
from zep_cloud.types import SearchFilters, MetadataFilterGroup, EpisodeMetadataFilter
# Only retrieve facts from verified EHR or lab sources
results = client.graph.search(
user_id="pt_5678",
query="patient allergies and current medications",
scope="edges",
search_filters=SearchFilters(
episode_metadata_filters=MetadataFilterGroup(
type="and",
filters=[
EpisodeMetadataFilter(
property_name="verified",
property_value=True,
comparison_operator="=",
),
],
groups=[
MetadataFilterGroup(
type="or",
filters=[
EpisodeMetadataFilter(
property_name="source",
property_value="ehr_intake",
comparison_operator="=",
),
EpisodeMetadataFilter(
property_name="source",
property_value="lab_report",
comparison_operator="=",
),
],
),
],
),
),
)The filter reads naturally: give me facts that are verified AND came from either EHR intake or lab reports. Facts derived from unverified chatbot conversations are excluded, not because they were deleted, but because retrieval was scoped to authoritative sources. The data remains in the graph for other use cases that don't require the same clinical rigor.
This is provenance working in two directions. Looking backward, you can trace any piece of context to its source. Looking forward, you can scope retrieval to specific sources before the agent ever sees the context. Same provenance metadata, two directions of value.
Metadata filters can be combined with entity type filters, property filters, and date range filters for multi-dimensional control over what context reaches the agent. See the full documentation for the complete filter syntax and supported operators.
Agents That Reason Over Provenance
Metadata filters don't have to be hardcoded. When graph.search is exposed as a tool call, the agent itself can select filters dynamically based on the task at hand. A clinical agent assisting with a medication decision might autonomously restrict its search to verified EHR sources, while the same agent answering a general lifestyle question might search across all sources. The provenance metadata you tag on your episodes becomes a vocabulary the agent can reason over at runtime.
Why This Matters
Audit-ready by default. The provenance chain from context to source is structural, built into the graph, not bolted on. For regulated industries, the audit trail is already there.
Ingest everything, filter at retrieval. Episode metadata projection means you can ingest broadly across every source and filter precisely at query time. The more data in the graph, the richer the context. Provenance metadata ensures you can still control what reaches the agent.
Inspectable agents. When an agent gives an unexpected response, the provenance chain turns "why did it say that?" into a concrete path from response to source data. No black boxes.
Agent autonomy with guardrails. Agents that can reason over provenance metadata can dynamically scope their own context based on the task. Clinical rigor when needed, broader context when appropriate.
Zep is SOC 2 Type 2 certified and HIPAA-ready, with role-based access control for team-level permissions. Built for the security and compliance requirements of enterprise deployments.
Getting Started
Episode metadata and metadata filtering are available today on all Zep plans. To start building provenance into your agents:
- Tag your data at ingestion time using the
metadataparameter ongraph.add(). Define whatever keys describe your data's origin and characteristics. - Use metadata filtering in
graph.search()to scope retrieval by source - Combine with entity type filters, property filters, and date filters for multi-dimensional context control
Read the full documentation on episode metadata and metadata filtering, or get started with Zep.