How do you search a Knowledge Graph?
Can you build graph search that's both elegant & powerful? Here's how we did it in Graphiti, Zep's open source temporal Knowledge Graph library.

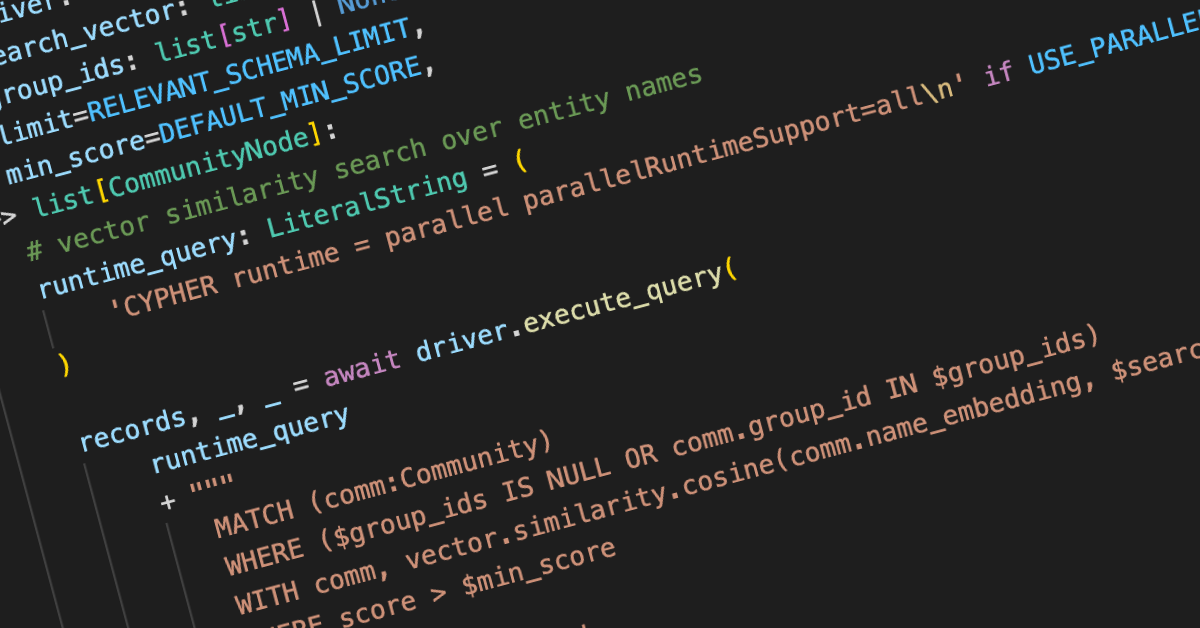
In previous posts, we explored how Graphiti transforms raw data into a dynamic knowledge graph. This article will delve into how Graphiti's architectural decisions enable us to build robust and powerful search capabilities. We'll also examine our vision for the evolution of these search techniques.
Graphiti currently offers two main search endpoints:
graphiti.search(): A high-level, opinionated search that returns relevant facts based on a query.graphiti._search(): A low-level search that allows for more granular control of search functionality.
For the remainder of this article, we'll focus on the functionality of graphiti._search().
Search Scope
Understanding Graphiti search begins with understanding the types of data it returns. Graphiti search currently has three search scopes: entity edges, entity nodes, and community nodes. Entity edges and entity nodes are often referred to simply as edges and nodes in this article, in the Graphiti code, and its documentation, as they represent the semantic data typically associated with knowledge graphs. Nodes represent entities extracted from the processed data and have name and summary fields as their text fields. Edges represent relationships between nodes and have a name that classifies the type of relationship, and a fact field that represents the hydrated fact between two entities.
Communities are an auxiliary node type that can be built during post-processing using graphiti.build_communities() and updated during subsequent graphiti.add_episode() calls, provided the update_communities boolean is set. This node type was inspired by Microsoft's GraphRAG paper, where communities are calculated using algorithms such as Leiden, Louvain, and Label Propagation to find strongly connected clusters of nodes. Community nodes are then created with edges to their member nodes. These nodes contain a summary field summarizing all member entities and a name field briefly describing the information in the summary. Community nodes are a powerful addition to Graphiti for retrieval, as they leverage the graph structure to produce higher-level contextualized information. Moreover, our strategy of building community summaries during processing rather than retrieval allows us to return information about entity interconnections without the extra latency overhead of using an LLM to build these summaries on the fly.
Each of these three search scopes is handled separately and has its own corresponding search config. The return type of graphiti._search() contains fields for all three; if a certain type is not included in the scope, its list will be empty.
Search Types
Currently, Graphiti supports three major search types for each search scope: semantic similarity search, full-text search, and breadth-first search (BFS). Neo4j's graph database handles all three methodologies, implementing Lucene vector search, Lucene full-text search, and using its native graph structure. The vector search uses cosine similarity for KNN search, while the full-text search employs a TF-IDF search—a modified version of BM25. LuceneQL powers this search, allowing for simple logical expressions within queries. Additionally, we enable a dynamic Levenshtein distance-based fuzzy search as part of our full-text search. These methods have become the standard for hybrid search, combining the high-recall capabilities of "things not strings" semantic search with the high-precision capabilities of string-match focused full-text search. We won't delve deeper into these methodologies here, as they're widely used in retrieval-augmented generation and well-documented elsewhere.
For edges, searches are performed over the edge fact, while for nodes and communities, the search focuses on the name field. This distinction in search fields stems from a separation of purpose. The facts search aims to retrieve precise information directly related to the query's semantics. In contrast, node searches are designed to fetch high-level information about specific entities. Community searches represent an even broader, more global search, matching results based on the type of information in the summary rather than its explicit content. To summarize:
- Edge search returns granular information based on query-fact similarity
- Node search provides contextual information about mentioned entities
- Community search offers high-level context based on the discussion topic
This three-pronged approach enables answering both "local" and "global" questions effectively.
In addition to semantic and full-text search, the graph structure enables the use of graph traversal algorithms, most notably breadth-first search (BFS). The BFS search implemented in Graphiti supports two ways of performing the search. In the first method, the user passes in specific bfs_origin_node_uuids on which to perform the BFS search. This method is useful for searches where center nodes are already known, like if the user wants to find information mentioned in recent episodes. The second method will be performed if no origin nodes are passed in. This method will take a “land and expand” approach, first performing the other searches and then using those results as the seed for the BFS. This approach helps to find additional contextually relevant nodes to those that have already proven to be semantically relevant. We see a lot of potential for future expansions and refinements of the BFS search, where certain paths may be favored based on semantic similarity or node and relationship types.
Rerankers
After obtaining initial search results, reranking is essential. Rerankers serve two primary purposes: (1) combining disparate search results with different scoring mechanisms into a single list, and (2) reordering candidate results based on the desired use case. Graphiti offers three rerankers applicable to all three search scopes: reciprocal rank fusion (RRF), maximal marginal relevance (MMR), and a cross-encoder reranker.
RRF is a widely used reranker algorithm primarily designed to combine multiple lists of search results. It works by assigning a score to each search result based on its reciprocal rank in each of the search result lists.
MMR, another common reranker method, balances the similarity between a query and a search result with the result's distinctiveness from other returned results. Its purpose is to deliver results that are not only relevant but also notably different from one another. MMR uses a lambda parameter (between 0 and 1) to balance two factors: cosine similarity with the query and negative maximal cosine similarity with other search results. A higher lambda value gives more weight to the similarity score, while a lower value emphasizes the result's distinctiveness.
Cross-encoder rerankers are LLMs that embed two pieces of text simultaneously, and output a score between 0 and 1 based on how similar the sentences are. Cross-encoders are transformer-based models but tend to be of comparable size to the more common bi-encoders (commonly referred to as sentence embedder models). Cross-encoders will add extra cost and latency compared to other rerankers, but they will often produce higher quality results. There are also many cross-encoders that are trained on domain-specific data, which can further improve reranking quality within that business domain.
In addition to the above rerankers, Graphiti provides two specific rerankers for edges and nodes. The first is the node_distance_reranker. This reranker requires a UUID of a center node as input. It then reranks nodes and edges based on their proximity (in hops) to the center node. This method allows developers to bias results towards a particular relevant entity, such as a node representing the user.
The final reranker Graphiti offers is the episode_mentions_reranker. When ingesting episodes, Graphiti tracks entity and edge mentions, even for pre-existing ones. This enables the episode mentions reranker, allowing developers to rerank nodes and edges based on their frequency in previous conversations and ingested documents. This reranking biases results towards frequently appearing topics and entities, skewing responses towards content more relevant to the overall conversation.
Rerankers are one of the most effective ways to enhance search result quality. However, they're not one-size-fits-all solutions. Each reranker has its own trade-offs and biases, so it's up to Graphiti users to determine which reranker best suits their specific scenario. We plan to add more rerankers over time to further improve search flexibility.
Search Configs and Recipes
As this article demonstrates, Graphiti's search functionality is highly modular and offers a wide range of options. In software, such flexibility often results in complex, intimidating solutions. To address this issue, Graphiti provides pre-made search "recipes" that cover common use cases, making it more accessible to users.
In Graphiti search, the functionality is controlled by the search_config field which has the following structure:
class SearchConfig:
edge_config: EdgeSearchConfig | None
node_config: NodeSearchConfig | None
community_config: CommunitySearchConfig | None
limit: int
The main search config is primarily made up of the configs from each of the three scopes. We will look at the structure of the edge_config as an example, the other two configs are similar and can be found here in the codebase.
class EdgeSearchConfig:
search_methods: list[EdgeSearchMethod]
reranker: EdgeReranker
sim_min_score: float
mmr_lambda: float
The search methods and rerankers are enums:
class EdgeSearchMethod(Enum):
cosine_similarity = 'cosine_similarity'
bm25 = 'bm25'
bfs = 'breadth_first_search'
class EdgeReranker(Enum):
rrf = 'reciprocal_rank_fusion'
node_distance = 'node_distance'
episode_mentions = 'episode_mentions'
mmr = 'maximal_marginal_relevance'
cross_encoder = 'cross_Encoder'
This structure in the config file facilitates a lot of flexibility in the search, expressed in a relatively compact format. However, we recommend that users of Graphiti mostly use the pre-made search recipes found here. Each of the recipes are named after their functionality and also have a short clarifying description. The currently available recipes are as follows:
# Performs a hybrid search with rrf reranking over edges, nodes, and communities
COMBINED_HYBRID_SEARCH_RRF
# Performs a hybrid search with mmr reranking over edges, nodes, and communities
COMBINED_HYBRID_SEARCH_MMR
# Performs a full-text search, similarity search, and bfs with cross_encoder reranking over edges, nodes, and communities
COMBINED_HYBRID_SEARCH_CROSS_ENCODER
# performs a hybrid search over edges with rrf reranking
EDGE_HYBRID_SEARCH_RRF
# performs a hybrid search over edges with mmr reranking
EDGE_HYBRID_SEARCH_MMR
# performs a hybrid search over edges with node distance reranking
EDGE_HYBRID_SEARCH_NODE_DISTANCE
# performs a hybrid search over edges with episode mention reranking
EDGE_HYBRID_SEARCH_EPISODE_MENTIONS
# performs a hybrid search over edges with cross encoder reranking
EDGE_HYBRID_SEARCH_CROSS_ENCODER
# performs a hybrid search over nodes with rrf reranking
NODE_HYBRID_SEARCH_RRF
# performs a hybrid search over nodes with mmr reranking
NODE_HYBRID_SEARCH_MMR
# performs a hybrid search over nodes with node distance reranking
NODE_HYBRID_SEARCH_NODE_DISTANCE
# performs a hybrid search over nodes with episode mentions reranking
NODE_HYBRID_SEARCH_EPISODE_MENTIONS
# performs a hybrid search over nodes with episode mentions reranking
NODE_HYBRID_SEARCH_CROSS_ENCODER
# performs a hybrid search over communities with rrf reranking
COMMUNITY_HYBRID_SEARCH_RRF
# performs a hybrid search over communities with mmr reranking
COMMUNITY_HYBRID_SEARCH_MMR
# performs a hybrid search over communities with mmr reranking
COMMUNITY_HYBRID_SEARCH_CROSS_ENCODER
We recommend experimenting with different rerankers to better understand what situations each reranker excels in. We are also open to any feedback, and in particular suggestions for additional rerankers or search methodologies that would be essential for certain use cases.
Lookups
In addition to the search methods requiring a query input to find information in the graph, Graphiti offers various other methods for retrieving data. At Zep, we use the term "lookup" methods for these non-search retrieval techniques. Notably, Graphiti includes a comprehensive suite of CRUD operations for all edge and node types.
Graphiti also provides two other significant lookup methods. The graphiti.get_episode_mentions() method accepts a list of episode UUIDs and retrieves all nodes, edges, and communities mentioned in these episodes. This allows developers to access all relevant information from a set of episodes. This method is particularly useful as it avoids the overhead of embedding a sentence or calculating search results—ideal when relevant messages are already known (e.g., when a developer needs information from the previous n messages or a specific ingested document).
Complementing get_episode_mentions is the get_episodes_by_mentions function. It takes a list of nodes and edges and returns a list of episodes where these elements appear most frequently. This method is valuable for citations or direct quotations, enabling developers to easily trace the source of information retrieved through Graphiti's search endpoint.
As with our search functionality, we plan to continue refining our lookup functions. Our goal is to enhance these features to complement the search functionality and address use cases where traditional search methods may not be optimal.
Conclusion
One of the most exciting aspects of working with Graphiti has been the constant discovery of how powerful and flexible the underlying graph structure is. The architecture of Graphiti, discussed in our previous two articles, creates a solid foundation from which we can explore its optimal use. The development of search methodologies atop Graphiti's architecture presents a different style of development—starting with simple, proven methods and iteratively building upon them for ever-improving results.
As this article demonstrates, Graphiti's search capabilities have already matured, offering powerful and flexible features. The team at Zep has many more ideas in the pipeline. In the future, we plan to experiment further with LLM-based search methodologies and use custom schemas to enhance result filtering and searching. We'd love to hear how searching with Graphiti works for you and what additions would elevate your Graphiti search experience.
Next Steps
- Visit the Graphiti GitHub repo
- Read: Scaling Data Extraction: Challenges, Design Decisions, and Solutions for the first installment
- and Beyond Static Graphs: Engineering Evolving Relationships for the previous installment.